BUAA-OS-lab1
lab1 实验报告
思考题
Thinking 1.1
不妨先编写一个简单的 C 程序 helloworld.c。
1
2
3
4
5
#include <stdio.h>
int main() {
printf("hello world!\n");
return 0;
}
然后,我们首先对这个文件进行预处理(不进行编译和链接),并将结果输出到一个文件 temp 里。
执行 mips-linux-gnu-gcc -E helloworld.c > temp 命令,其中 -E 参数表示只进行预处理,不进行编译和链接操作。得到的部分结果如下。
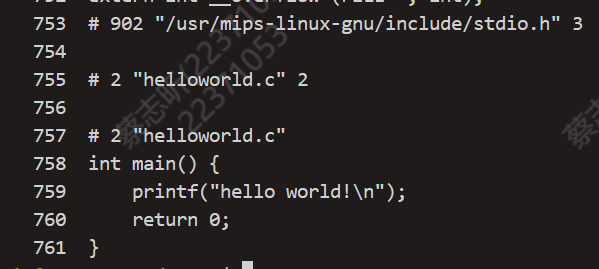
不难发现,预处理之后得到的结果只是将源代码中的头文件展开替换成了相应的代码,并没有进行任何的编译和链接操作。
执行下面两个命令:
1
2
mips-linux-gnu-gcc -c helloworld.c
mips-linux-gnu-objdump -DS helloworld.o > temp
这两个命令分别是针对 MIPS 架构的交叉编译和反汇编的操作。
第一个命令
mips-linux-gnu-gcc -c helloworld.c的含义是使用交叉编译器mips-linux-gnu-gcc对helloworld.c文件进行编译,生成目标文件helloworld.o。选项-c表示编译源文件但不进行链接,生成的目标文件通常用于后续的链接操作。第二个命令
mips-linux-gnu-objdump -DS helloworld.o > temp的含义是使用mips-linux-gnu-objdump工具对目标文件helloworld.o进行反汇编,并将反汇编结果输出到名为temp的文件中。选项-DS表示以十六进制和符号的形式显示反汇编内容。
得到的结果如下:
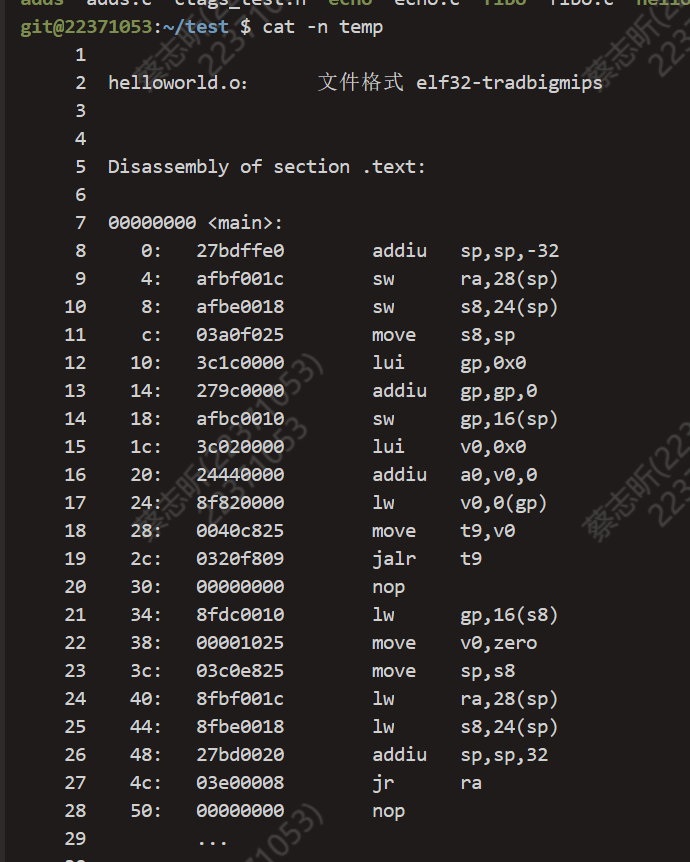
不难发现,反汇编的结果中包含了源代码中定义的变量和函数,以及编译器自动生成的诸如 .section 等一些汇编指令。
执行下面两个命令:
1
2
mips-linux-gnu-gcc -o helloworld helloworld.c
mips-linux-gnu-objdump -DS helloworld > temp
这两个命令是用于编译和反汇编 MIPS 架构程序的操作。
第一个命令
mips-linux-gnu-gcc -o helloworld helloworld.c的含义是使用交叉编译器mips-linux-gnu-gcc编译helloworld.c文件,并将生成的可执行文件命名为helloworld。选项-o helloworld指定了生成的可执行文件的名称。第二个命令
mips-linux-gnu-objdump -DS helloworld > temp的含义是使用mips-linux-gnu-objdump工具对名为helloworld的可执行文件进行反汇编,并将反汇编结果输出到名为temp的文件中。选项-DS表示以十六进制和符号的形式显示反汇编内容。
得到的结果如下:
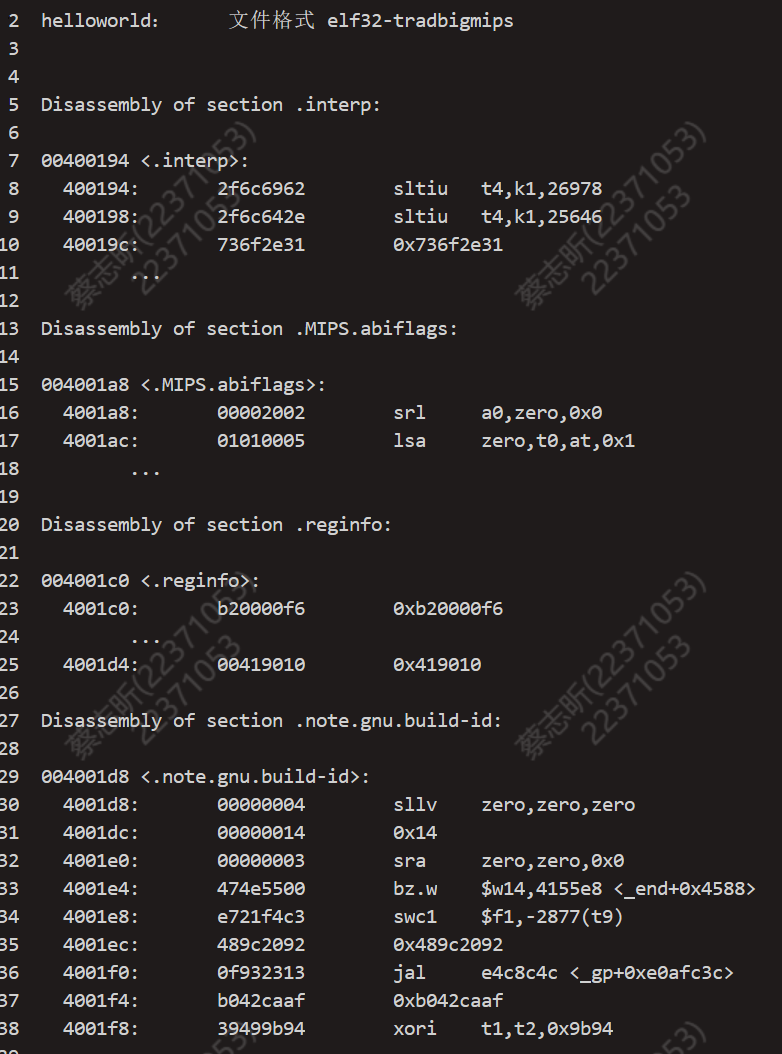
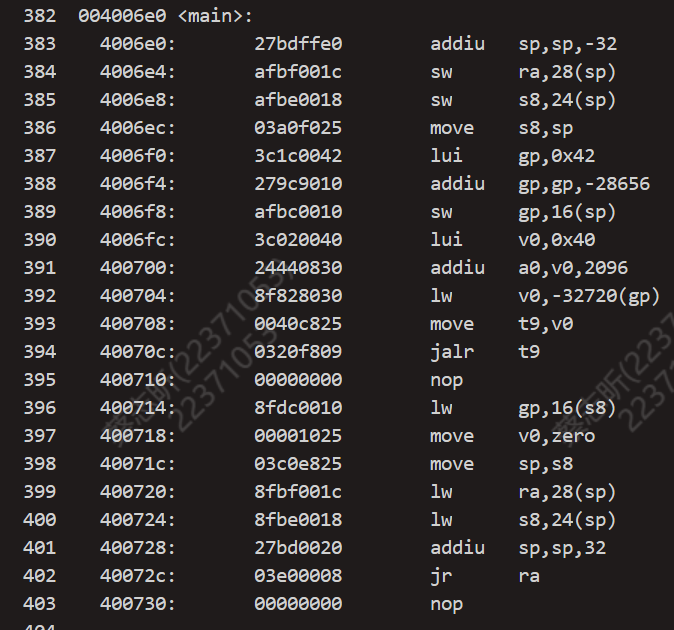
在这里我们发现,main 函数被分配到 004006e0 的地址,这是链接后得到的产物。
观察不同命令参数后得到的结果,并查阅相关的资料,可以得出以下结论:
在编译阶段,编译器会将源代码转换为目标代码(通常是机器代码),而链接阶段则会将多个目标代码文件组合在一起,解析符号引用,并生成可执行文件。因此,只编译不链接和编译链接得到的结果存在以下区别:
只编译不链接:
- 生成目标文件(.o 文件),包含了编译后的机器代码和符号表信息,但还没有进行符号解析和地址重定位。
- 如果涉及多个源文件,每个源文件都会生成对应的目标文件,但它们并未合并在一起。
编译链接:
- 将各个目标文件连接在一起,解析符号引用,填充地址空间,并生成最终的可执行文件。
- 在链接过程中,可能还会包含库文件、共享对象等,以及进行符号解析和地址重定位。
因此,只编译不链接得到的结果是目标文件,无法直接执行,而编译链接得到的结果是可执行文件,可以直接运行。
Thinking 1.2
对内核ELF文件使用命令 ./readelf ../../target/mos 进行解析,我们得到了一系列地址信息。然而,当尝试使用我们编写的readelf程序去解析自身时,却发现无法成功。这一问题的根源在于,我们编写的 readelf 程序仅支持解析 32 位 ELF 文件,而程序自身实际上是一个 64 位的 ELF 文件。
为了验证这一结论,我们首先使用 readelf -h 命令分别对 hello 和 readelf 文件进行了头部信息解析。对于 hello 文件,结果显示其类别为 ELF32,即 32 位 ELF 文件。而 readelf 文件则显示为 ELF64,即 64 位 ELF 文件。这一对比结果直接支持了我们的结论。
综上所述,我们编写的 readelf 程序无法解析自身的原因在于其仅支持解析 32 位 ELF 文件,而程序自身为 64 位 ELF 文件。这一发现为我们后续优化和扩展 readelf 程序的功能提供了重要的方向。
Thinking 1.3
根据附录对 bootloader 的介绍,可以了解到,在真实操作系统的启动过程中,内核的加载和运行并非一蹴而就,而是需要经过两个由 bootloader 控制的阶段:stage1 和 stage2。具体来说,stage1 主要负责硬件初始化工作,为 stage2 的运行准备 RAM 环境,并跳转到 stage2 的入口函数。而 stage2 则进一步初始化硬件设备及其他功能,把内核镜像加载到 RAM 中,并设置启动参数,设置内核入口函数的地址,以便把控制权转交给操作系统内核。
而在我们的实验中,启动流程被简化了,只需要把内核加载到 RAM 里,然后跳转到内核的入口。
而在 lab1 的课下,我们也进行了这部分的操作,我们先使用 Linker Script 设置每个节的地址,然后再设置 start.S 中的相关地址,并跳转到相应的函数,从而完成内核的加载和启动。
实验难点分析
这次实验首先是完成了内核位置的调整和 start.S 的代码补充,这是内核启动的一些准备工作,代码量比较小,但需要结合目录中的一些其它文件内容来进行代码补充,例如补充 kernel.lds 时,需要阅读目录下的内存布局图文件,从中分析位置的填写;补充 start.S 时,也需要阅读相应的文件,从宏定义中找出所需要的位置。
然后,课下实验还完成了两段 C 代码的补充,一个是模拟 readelf 的行为,虽然填的空并不多,实现的功能也比较简单,但是整个代码的框架还是搭的比较大,需要仔细阅读很多相关的变量、结构体的定义,才能从中找到相应的变量,完成代码的编写。另一个是 printk 函数的实现,这个内容其实并不难,主体部分已经全部实现好了,代码填空只需要补充一些逻辑过程性的部分就可以了。然而,想要真正理解 printk 函数,还是需要把三个文件的内容、逻辑框架看懂,理清每个函数分别的作用,以及每个参数的含义,这样才可以在上机的时候驾轻就熟。
上机实验的题目,exam 是对 printk 增加一个功能,这个相对来说比较简单,只需要在识别百分号后的 case 语句里增加一个判断,再仿造%d 和 %c 部分的内容完成输出即可。extra 是完成一个 scan 函数,这个也不难,在课下理解了 printk 函数的实现逻辑的话,还是很容易完成的,依葫芦画瓢完成参数列表的传递、参数的取用、内容的分类读取即可。
实验体会
这次实验总体来说需要我们完成的内容并不是很多,难度也不大,但很重要的一点是要仔细阅读现有的代码,可以说,这次实验里,读代码的能力远比写代码的能力更重要。只要把已有的架构彻底的理解清楚了,代码的编写与补全也就水到渠成了。
另外,在读代码的过程中,我也对 C 代码有了更多的认识,学习到了以前没有接触过的一些用法,比如回调函数、变长参数等。并且,阅读现有的代码,让我更深刻的理解到了工程性的代码应该怎么完成,以及命名、函数框架等的细节。