Improving Factuality and Reasoning in LLM through Multiagent Debate
多智能体辩论提高语言模型的真实性和推理能力
https://arxiv.org/abs/2305.14325
Abstract
提出了一种改进回答的方法,多个语言模型 在多轮次中提出它们自己的回答和推理过程并为此辩论,从而得到一个共同的最终答案。研究结果表明,这种方法在许多任务中都能显著提高模型的数学和策略性推理能力。这种方法提高了生成内容的事实性,减少了现在的模型容易产生的错误答案和模型幻觉。这个方法可以直接用于现在的 黑盒模型,用 相同的过程和 prompt 来解决所有任务。总得来说,这个研究表明,这种“社会思想”的方法有可能显著提高 LLM 的能力,并为语言生成和理解的进一步突破铺平了道路。
项目网站:https://composable-models.github.io/llm_debate/.
Introduction
LLM 在互联网上大量文本语料上训练,质量和准确性无法得到保证。
现有办法:These range from prompting models with few or zero-shot chain-of-thought demonstrations, use of verification, self-consistency, or intermediate scratchpads.
这些技术都是作用与单个模型上的。受 The Society of Mind 和多智能体的启发,提出了一种方法,让多个模型或智能体提出并共同讨论他们的回答和推理过程,来得出一个共同的答案。给定一个查询,每个模型都生成一个候选答案,然后 读取并评价其它模型的回答,并更新自己的答案,重复多轮。在给出最终答案之前,模型都可以维护多个推理链和可能的答案。
baseline: zero-shot chain of thought,reflection, reflection2。总之就是比这两种效果好。
给定一个初始的询问,虽然模型相同,但是每个模型实例提出了不同答案(也研究了混合模型,如 chatGPT 和 Bard)。debate 过后,模型们总是会收敛于一个更准确的答案,答案也不太可能包含模型不确定的错误事实,因为不确定的事实会让不同模型产生分歧,从而不在最终结果中出现。debate 不仅仅是放大一个正确答案,因为很多时候,模型一开始的答案是错的,但是在辩论进行中慢慢得出了正确答案。
用相同的方法和 prompt 模板,黑盒模型就行,不需要模型内部信息。虽然 debate 的成本更高,要多个模型和多轮辩论,但他的答案得到了显著改善,并可以用于生成一些模型训练数据,让模型可以自我完善。
引入了一个新的 benchmark 和 dataset 来评估事实准确性。现代的语言模型有很高的倾向去生成与事实不相符的人物传记,歪曲相关的日期和机构组织,而且这些信息,不同模型生成出来的一般会不一致。通过要求模型达成共识,这些不一致的事实可能会被删除或者被被纠正。
工作:
- 提出了一个 debate 的方法
- 引入了一个关于事实准确性的 benchmark
- 评估 debate 过程的生成表现
Language Generation through Multiagent Debate
下图是一个 debate 的例子。
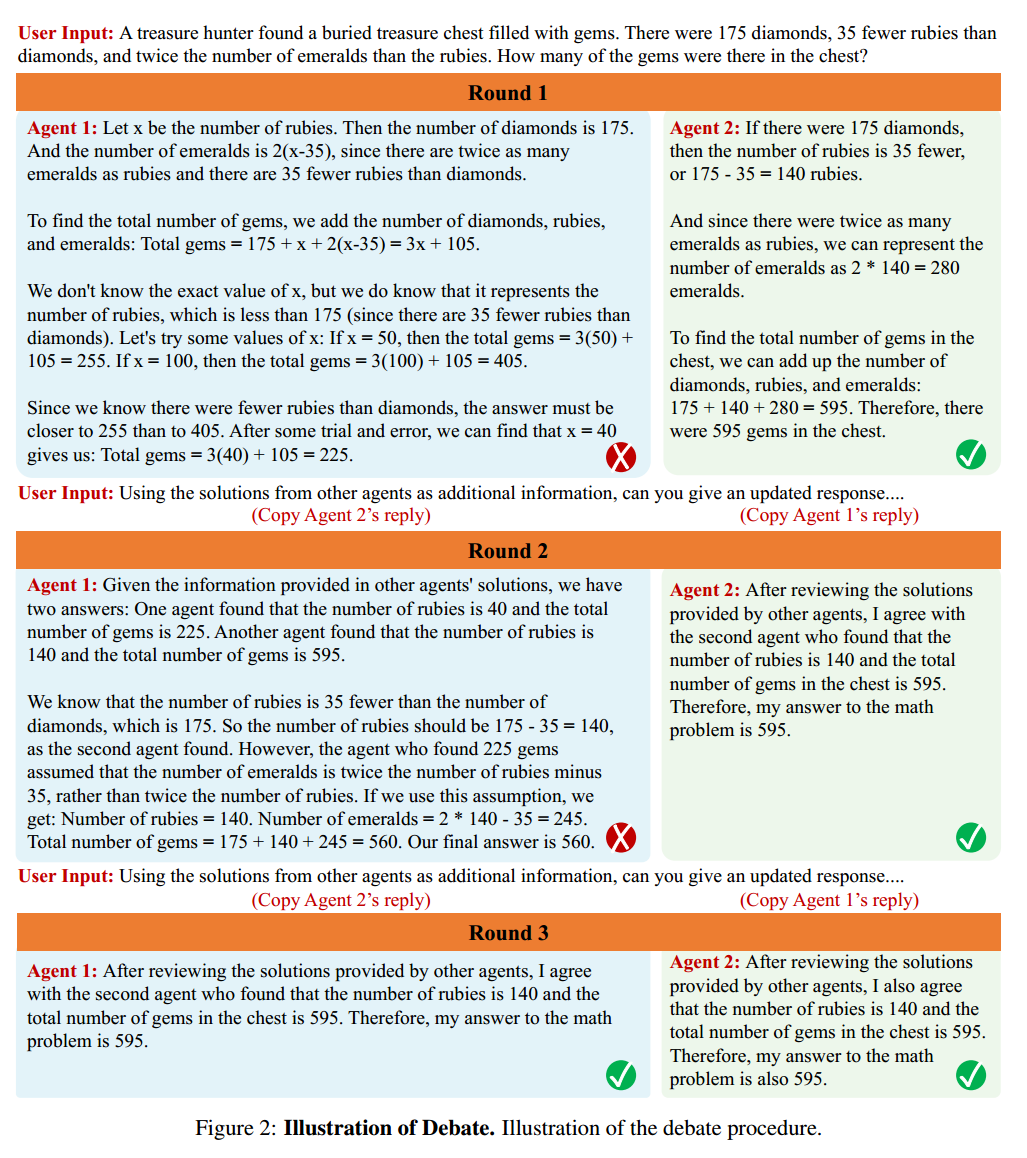
每一轮的 prompt:Using the solutions from other agents as additional information, can you give an updated response….
Multiagent Language Generation
每个智能体先产生初始回答,然后把其它智能体的回复连接起来,作为 context 提供给每一个智能体,然后每个智能体又根据这个产生新的回复。每个智能体负责验证其它智能体给出的回复,并且据此改进自己的答案。反复重复这个过程。
先让每个智能体独立解决给定的问题,然后给一个相同的 prompt:

这个 prompt 可以一直用,把内容换成上一轮的生成内容就行。
这个方法和现有的 prompt 方法 orthogonal (正交的)。(?)
可以用额外的技术来 prompt 模型,引出更详细的回答来改进 debate 过程。
Consensus in Debates
怎么保证一组模型最后会收敛于一个共识性的答案?根据实验发现一定会收敛。
可以通过改变模型对自己输出的信任程度来控制辩论时间,用上面 Figure 3 的 prompt 来控制辩论持续时间。鼓励模型坚持于自己的观点的 prompt 会带来更长时间的辩论和更好的解决方案。
Experiments
讨论的问题:
- Debate 在多大程度上提高了 推理能力(reasoning)?
- Debate 在多大程度上提高了 事实有效性(factual validity)?
- 什么样的 设计 能提高多智能体辩论的语言生成性能?
Reasoning
在三个难度越来越大的推理任务中进行评估:
- Arithmetic 算数
- GSM8K 小学数学
- Chess Move Prediction 国际象棋走法预测,给出前 14 步,预测下一步最好应该怎么走。
baseline:和三种方法进行比较。
- 单智能体
- 让模型生成后进行“self-reflect”
- 多智能体生成 response 后进行投票
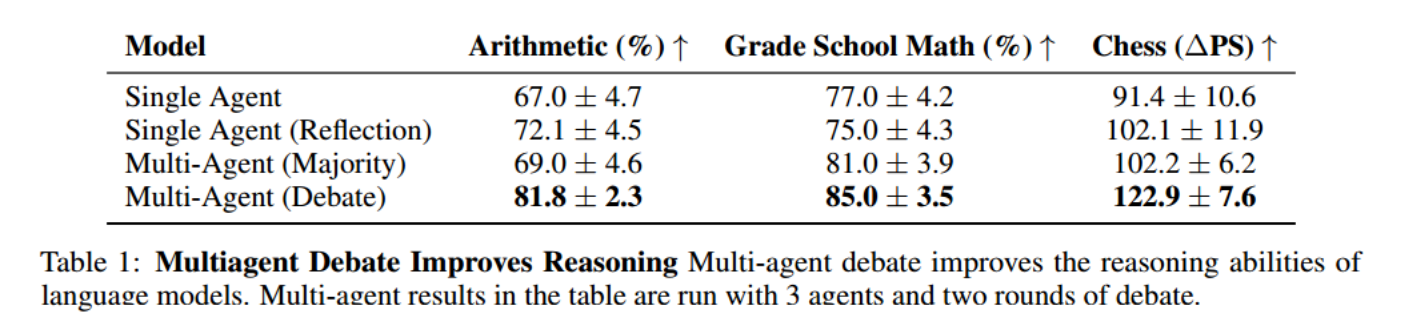
考虑到开销问题,使用三个智能体,两轮辩论来评估。
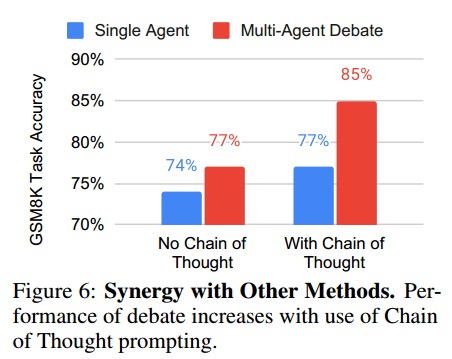
定量结果分析:相比单智能体,多智能体生成解决方案提高了性能;当模型被要求对自己的生成进行批评时(slef-reflect),会提高性能;多智能体辩论可以视为是 reflection 和多智能体生成的结合。
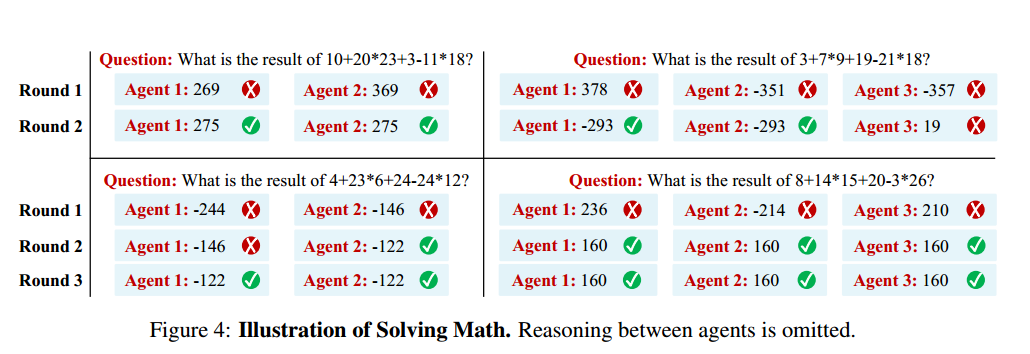
定性结果分析:虽然所有模型最初都给出了错误的答案,但是辩论后得到了正确的答案。因此辩论的目的不仅仅是为了放大某一个正确答案。
Factual
在三种不同的环境下评估语言模型的真实性。
Biographies:构建 524 位计算机科学家的真实传记,要求模型为每个人生成传记,评估生成的传记和真实传记的一致准确性。
MMLU:现有的 MMLU 数据集,评估模型回答不同的事实性和知识问题(像考试题一样)时的准确性。
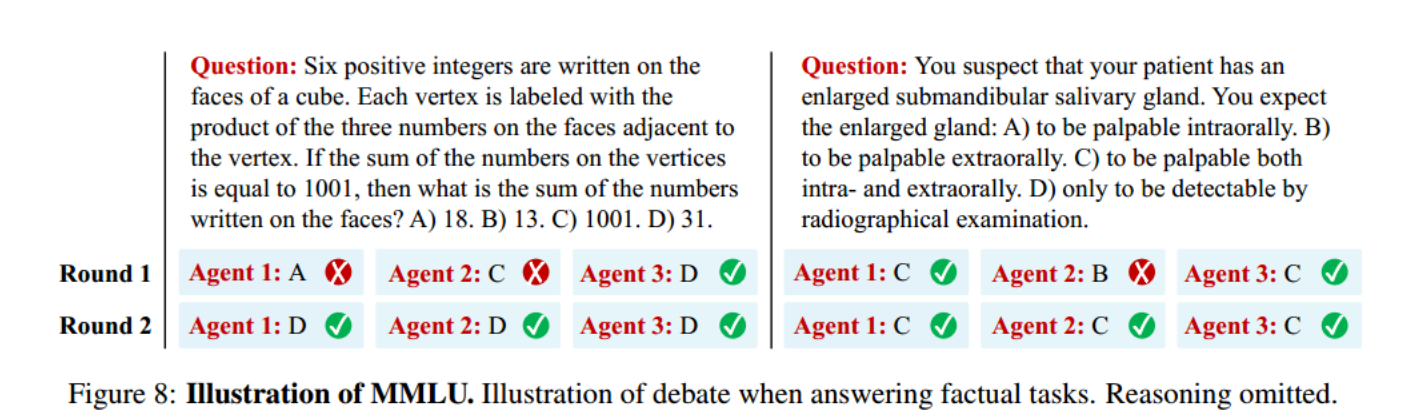
Chess Move Validity:BIG-Bench Chess-State Tracking Benchmark,给一个既定的规则,然后给一个下一步的走法集合,模型选择一个走法。
baseline:同上,删去多智能体投票。
结果:reflection 表现不佳,debate 表现很好。
当模型对问题不确定时,不同的智能体倾向于给出不同的答案;但直接询问每个智能体对答案的置信度,会导致每个答案的置信度评分都很高。debate 时智能体会迅速改变观点,获得更准确的共识性答案。
Analysis: Understanding Multiagent Debate
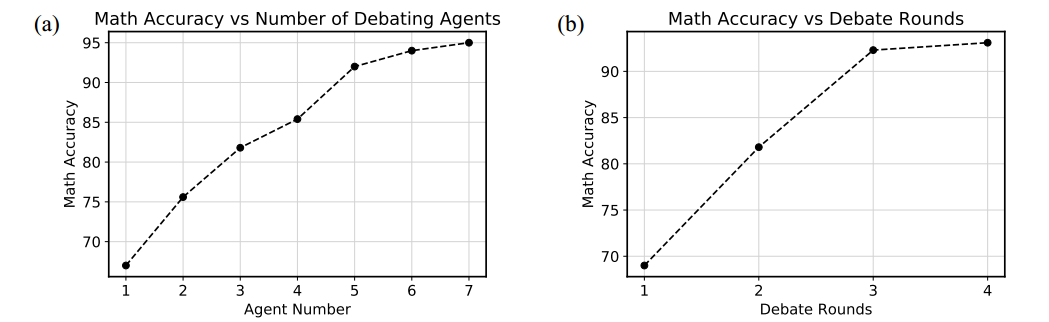
智能体数量。固定辩论次数为两次,增加智能体数量,性能随着智能体数量增加而增加。智能体数量多的时候,先用 chatGPT 总结所有智能体的 response,以免直接连接而造成上下文长度过长。
辩论轮数。固定智能体数量为三个,增加辩论轮数,性能随辩论轮数增加而增加。4 轮以上的辩论最终表现和 4 轮相似。
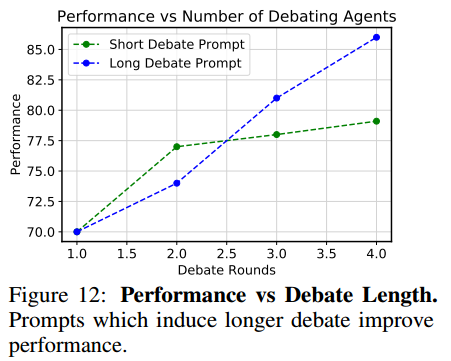
辩论长度。用 prompt 控制答案收敛的程度,从而控制辩论持续的长度。长 prompt 的辩论导致收敛速度慢,但最终的答案更好。

使用不同的初始 prompt。让不同的模型在 MMLU 数据集上表现得像不同的角色,这会提高性能。
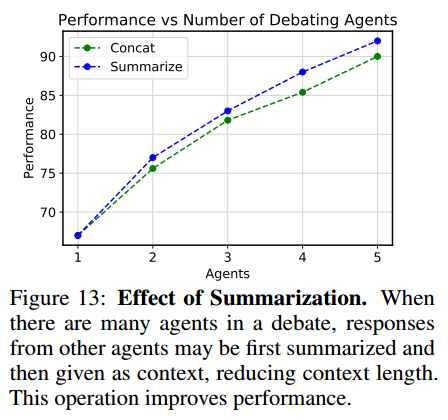
总结。智能体数量较多时,直接把 response 连接起来会使成本增大,可以将所有其他智能体的 response 总结成一个 response。会提高性能。
利用不同的模型。现有结果是用 chatGPT 的 instance 来做的,进一步用了两种不同的语言模型,chatGPT 和 Bard 在 20 个 GSM8K 数学问题上进行辩论,结果发现提高了性能。
