多智能体相关实验总结
阅读多智能体相关的论文,着重关注其中实验部分,总结他们用了什么 benchmark,在测试模型的哪些能力,结果怎么样。
Mixture-of-Agents
- 只用开源模型,部分指标优于 GPT-4o
- 大量实验有助于了解 MoA 内部机制
- 成本效益提高两倍以上,并提供与 GPT-4 Turbo 相当的性能
Setup
Benchmark
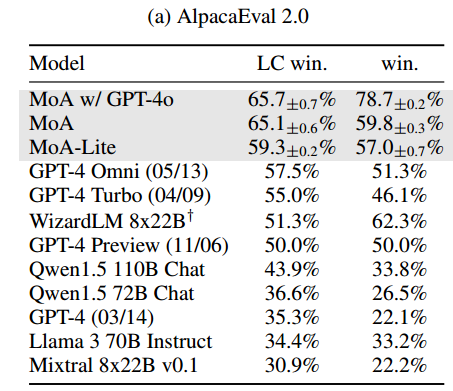
主要在 AlpacaEval 2.0 (Dubois et al., 2024) 上进行评估,包含 805 条 实用指令,每个模型的回答 与 GPT-4 进行对照比较,再 用 GPT-4 作为评估者,得出使用者更喜欢被评估模型回答的可能性。采用了 length-controlled win rate,来消除 length bias。
还在 MT-Bench 和 FLASK 上进行评估,MT-Bench 用 GPT-4 来给模型的答案打分,FLASK 的评估更加精细,包含了 12 个特定技巧的评分。
Models
MoA 用开源模型来构建,包括 Qwen1.5-110B-Chat (Bai et al., 2023), Qwen1.5- 72B-Chat, WizardLM-8x22B (Xu et al., 2023a), LLaMA-3-70B-Instruct (Touvron et al., 2023b), Mixtral-8x22B-v0.1 (Jiang et al., 2024), dbrx-instruct (The Mosaic Research Team, 2024). 构建了三层,每一层中使用相同的模型集,用 Qwen1.5-110B-Chat 作为最后的整合者。
开发了一个变体 MoA w/ GPT-4o,用 GPT-4o 作为最后一层的整合器,生成更高质量的输出。
另一个变体 MoA-Lite 强调性价比(考虑成本),模型集相同,但是只构建了两层,用 Qwen1.5-72B-Chat 作为整合器。这让它比 GPT-4o 更便宜,并且在 AlpacaEval 2.0 上比 GPT-4o 强出 1.8%。
Benchmark Result
AlpacaEval
与 GPT-4 这样的 leading models 和其它优秀的开源模型进行比较,结果如下表。只用开源模型就比 GPT-4 好,并且注重经济效益的轻量版 MoA-Lite 也比 GPT-4 好一些。说明在各种算力下,我们的方法都可以充分利用开源模型,发挥出它们的最大潜力。
MT-Bench
在 MT-Bench 上的改善相对来说不是特别明显,因为现有模型在这个 Benchmark 上表现已经很好了,都可以获得 9/10 的分数。不过 MoA 还是保持在榜首。这表明,即使是在这种被高度优化的基准,MoA 也可以进一步把边界拓宽,保证领先地位。
FLASK
FLASK 对模型进行更加细致的评估。在 robustness, correctness, efficiency, factuality, commonsense(具有常识的), insightfulness(洞察力), completeness(完备性), 方面优于 Qwen-110B-Chat,在 correctness, factuality, insightfulness, completeness, and metacognition(元认知) 方面优于 GPT-4 Omni。MoA 在 conciseness(简洁性)指标上做的不好。
What Makes Mixture-of-Agents Work Well?
进行实验,更好的理解 MoA 的内部机制。
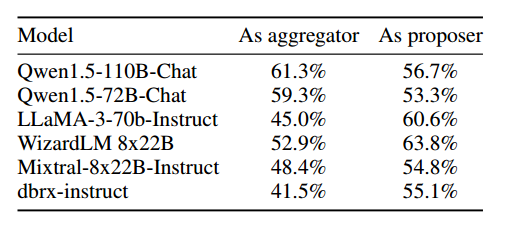
MoA 表现得比 LLM-ranker 要好。LLM-ranker 是指,用一个整合器来从提议者给出的答案中 选择 一个,而不是生成一个新的答案。结果如下图,可以看出 MoA 远比 LLM-ranker 要好。这表明整合器不是简单的选择,而是进行聚合。
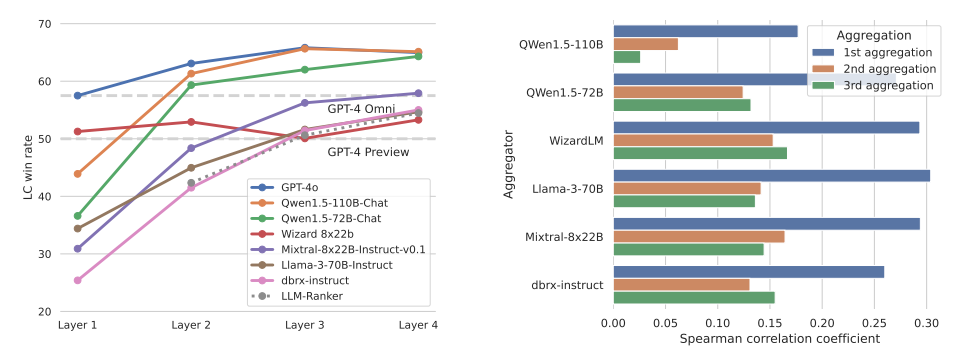
MoA 的提议者都一样,选用不同的模型作为最后的整合器。
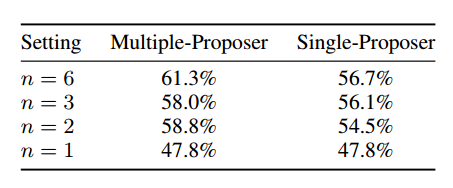
模型多样性和提议者数量的影响。通过改变每层的提议者数量,分析提议者数量对结果质量的影响。结果如下表,表明提议者越多,辅助信息越多,结果质量越好。比较了每层 n 个回答是用同一个 LLM 还是不同的 LLM,发现 multiple 的结果更好一些。这两个结果都表明,在每层里有更多不同的 LLM 可以提高性能。
GPT-4o, Qwen, LLaMA-3 在辅助和整合上都表现很好,WizardLM 是好的提议者,不是好的聚合者。
Budget and Token Analysis
分析 budget,token usage,LC win rate 之间的关系。
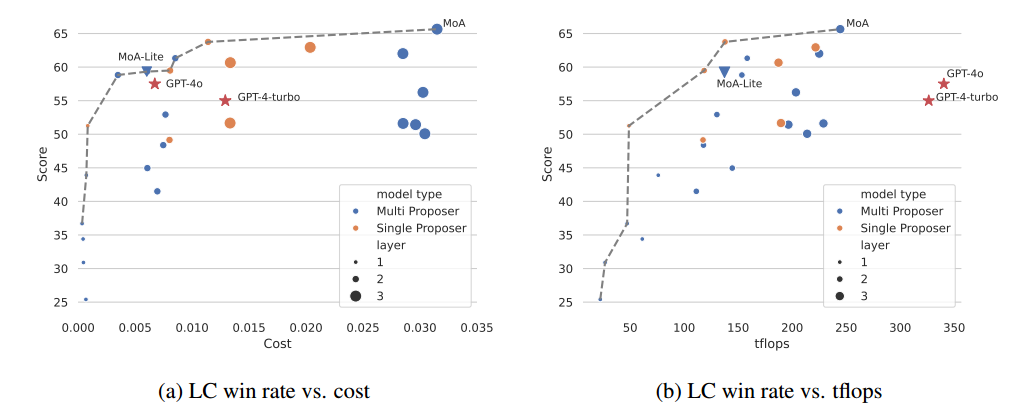
tflops:GPU 每秒可执行的浮点操作次数,是衡量 GPU 性能的指标,在此代指 latency(衡量系统处理一个请求所需的时间,即处理单个任务的效率。因为延迟与整个系统有关,因此用 tflops 来代指)。每一层取最大 tflops,然后求和,因为可以并行。
画了一个 Pareto frontier,可以选取分数高,成本低的模型。发现 GPT-4 不在这个线上,他们不是成本最优的。
GPT-4 的 tflops 未知,用 8x200B architecture 的大小来代替。
- 成本效益:5a 图中计算了所有 AplacaEval 2.0 中每个用例的平均推理成本,cost 是通过 api 提供者的网站上的定价信息来计算出的。Pareto frontier 上的模型在成本和性能之间达到了最佳平衡,更接近这个 frontier 的模型更好,可以用更低的成本提供更高的 LC win rate。考虑生成质量,用 MoA 最好,在质量和成本之间保持平衡,用 MoA-Lite 可以用和 GPT-4o 差不多的成本,达到更高的生成质量。
- tflops 消耗:代指响应速度,避免系统差异
Multiagent Debate(MIT)
讨论的问题:
- Debate 在多大程度上提高了 推理能力(reasoning)?
- Debate 在多大程度上提高了 事实有效性(factual validity)?
- 什么样的 设计 能提高多智能体辩论的语言生成性能?
Reasoning
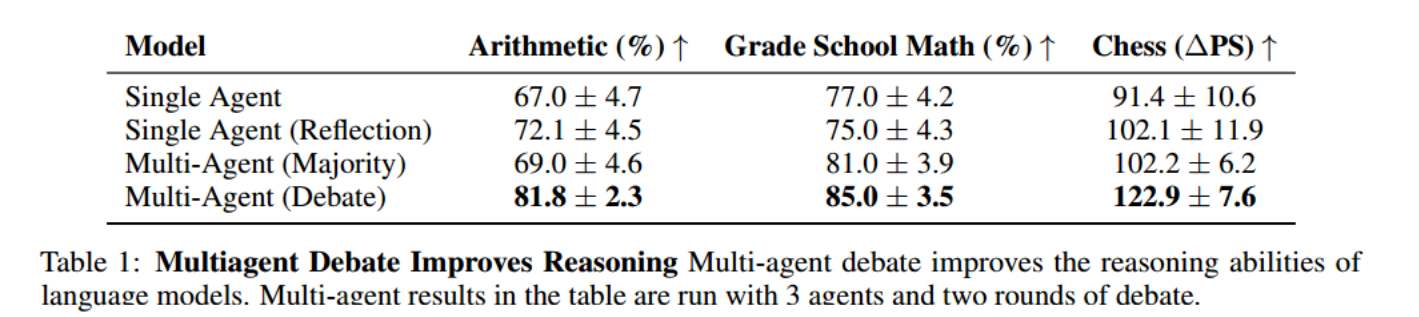
在三个难度越来越大的推理任务中进行评估:
- Arithmetic 算数
- GSM8K 小学数学
- Chess Move Prediction 国际象棋走法预测,给出前 14 步,预测下一步最好应该怎么走。
baseline:和三种方法进行比较。
- 单智能体
- 让模型生成后进行“self-reflect”
- 多智能体生成 response 后进行投票
考虑到开销问题,使用三个智能体,两轮辩论来评估。
定量结果分析:相比单智能体,多智能体生成解决方案提高了性能;当模型被要求对自己的生成进行批评时(slef-reflect),会提高性能;多智能体辩论可以视为是 reflection 和多智能体生成的结合。
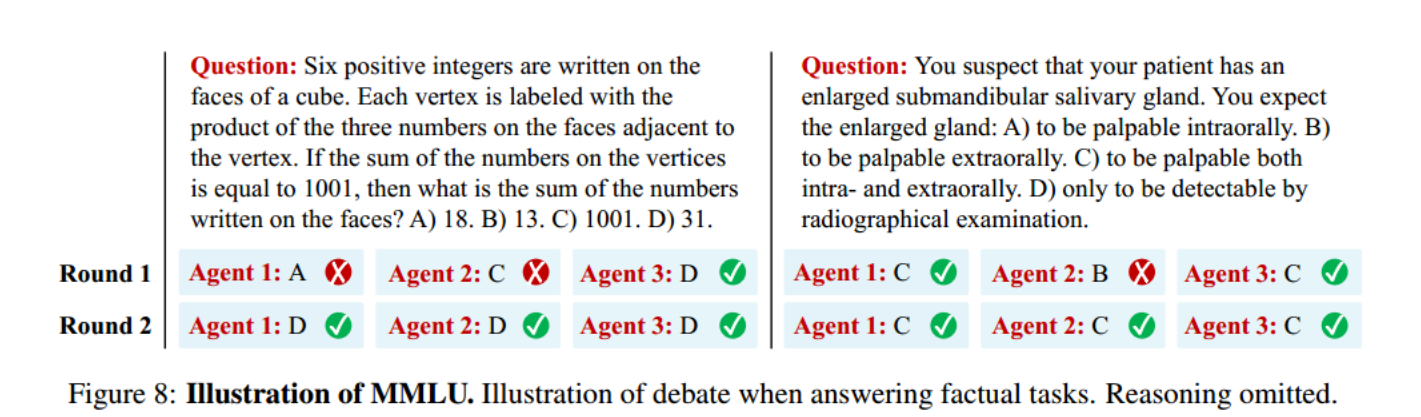
定性结果分析:虽然所有模型最初都给出了错误的答案,但是辩论后得到了正确的答案。因此辩论的目的不仅仅是为了放大某一个正确答案。
Factual
在三种不同的环境下评估语言模型的真实性。
Biographies:构建 524 位计算机科学家的真实传记,要求模型为每个人生成传记,评估生成的传记和真实传记的一致准确性。
MMLU:现有的 MMLU 数据集,评估模型回答不同的事实性和知识问题(像考试题一样)时的准确性。
Chess Move Validity:BIG-Bench Chess-State Tracking Benchmark,给一个既定的规则,然后给一个下一步的走法集合,模型选择一个走法。
baseline:同上,删去多智能体投票。
结果:reflection 表现不佳,debate 表现很好。
当模型对问题不确定时,不同的智能体倾向于给出不同的答案;但直接询问每个智能体对答案的置信度,会导致每个答案的置信度评分都很高。debate 时智能体会迅速改变观点,获得更准确的共识性答案。
Analysis: Understanding Multiagent Debate
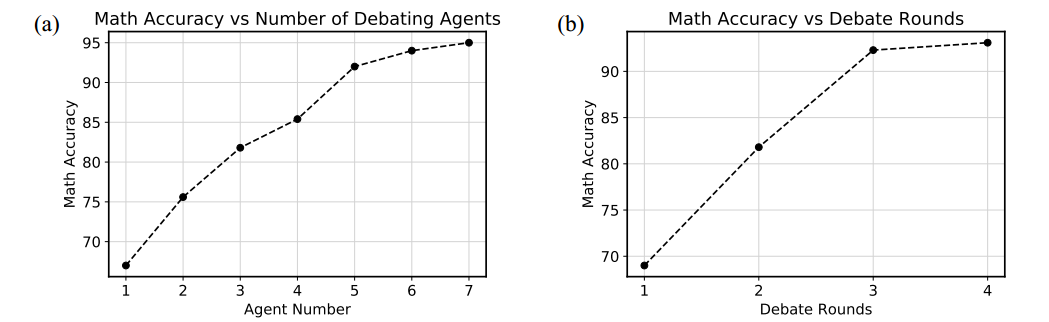
智能体数量。固定辩论次数为两次,增加智能体数量,性能随着智能体数量增加而增加。智能体数量多的时候,先用 chatGPT 总结所有智能体的 response,以免直接连接而造成上下文长度过长。
辩论轮数。固定智能体数量为三个,增加辩论轮数,性能随辩论轮数增加而增加。4 轮以上的辩论最终表现和 4 轮相似。
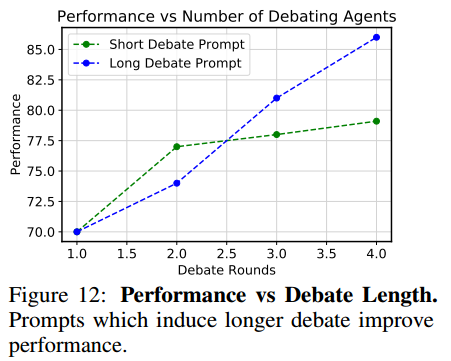
辩论长度。用 prompt 控制答案收敛的程度,从而控制辩论持续的长度。长 prompt 的辩论导致收敛速度慢,但最终的答案更好。

使用不同的初始 prompt。让不同的模型在 MMLU 数据集上表现得像不同的角色,这会提高性能。
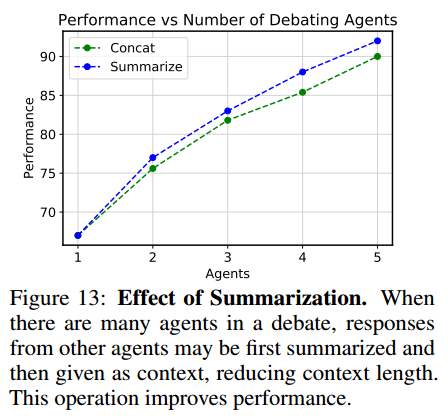
总结。智能体数量较多时,直接把 response 连接起来会使成本增大,可以将所有其他智能体的 response 总结成一个 response。会提高性能。
利用不同的模型。现有结果是用 chatGPT 的 instance 来做的,进一步用了两种不同的语言模型,chatGPT 和 Bard 在 20 个 GSM8K 数学问题上进行辩论,结果发现提高了性能。

Chateval
这篇文章主要是用 debate 实现了一个文本评估器,FairEval 和 Topical-Chat,分别代表开放性问题的回答和对话生成。
这篇主要是针对“文本评估”这一个专用领域的,和我们的研究貌似关系不大,没有细看。
实现细节
使用 OpenAI 的 GPT 模型,包括 GPT-4 和 ChatGPT(GPT-3.5 turbo),把温度设置为 0 以保证可复现。focus on 同质的 LLM 群体,多智能体组中所有 LLM 都属于相同的 GPT 模型,要么都是 GPT-4,要么都是 ChatGPT。
Benchmark
- Open-ended Question Answer(开放性问题),要求 AI 对没有固定答案的问题提供全面、详细、类似人类的回答。用了某篇论文中构造出的 80 个开放性问题的集合以及另一篇论文中的人工标注结果。
- Dialogue Response Generation(对话生成),对给定的输入对话生成连贯、符合上下文的 response。也是用了某篇论文的数据集和对应的人工标注结果,对多个维度进行了评估。
Baseline
主要是和单智能体的方法进行对比。此外,对于开放式问题的问答,与 FairEval 进行比较;对于对话生成任务,和 G-EVAL 进行比较。