LLM 学习笔记4-大模型训练
预训练,后训练(微调,对齐,RLHF)
预训练
Tokenization
任何信息都可以被转化为 Token,任何 Token 都可以被学习。
训练的第一步:Tokenization,把文本或其他信息分解为一个个离散的单元(Token)。
Embedding
Tokens 可以用 embeddings(词嵌入,将单词表示为向量,使得相似的单词在向量空间中距离更近)的方式进一步表示。
过去的预训练中,词向量是 上下文无关的,会受到语言的二义性的影响。
ELMo:情景化预训练的开始,词向量的表示和上下文有关,每个词向量结合了预训练深度神经网络的所有层。
Transformer:注意力机制,很适合训练上下文相关的词向量,每个 Token 会注意到和他相关的上下文 Token。
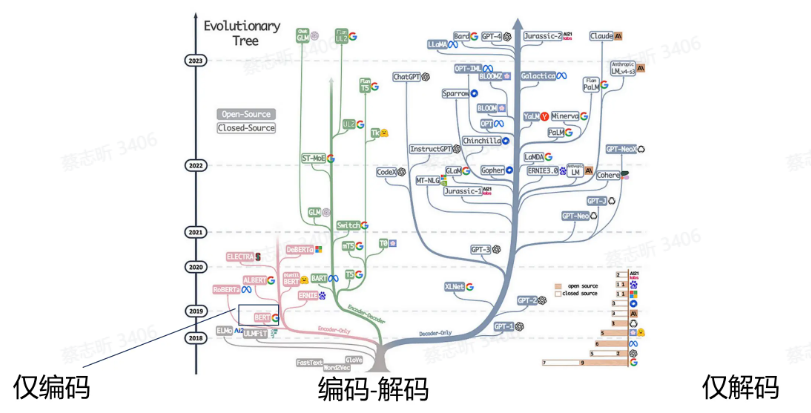
基于 Transformer 的预训练模型:
- Encoder-Only: Bert
- Encoder-Decoder: T5
- Decoder-Only: GPT
采用了 Transformer 的不同部分,采用不同的目标函数
GPT
第一个基于 transformer 的预训练语言模型。
从左到右的训练,利用前面的单词的概率预测下一个单词的概率,引入注意力掩码来控制哪些 Token 在注意力计算中是可见的,确保不去看到后面的单词。
Bert
显著改变 NLP 范式。
方法:对于输入的序列,随机 遮盖 掉其中的 k% 部分,然后预测被遮盖掉的词。BERT 中,k=15%。覆盖过少,训练成本高;覆盖过多,上下文不够。
Bert 和 GPT 不一样的地方:Bert 是 双向的 Attention,可以看到前后的上下文。
现在更多的模型:单向建模。
另一个目标函数:理解句子之间的关系,预测句子 B 是否是句子 A 之后的下一个句子。
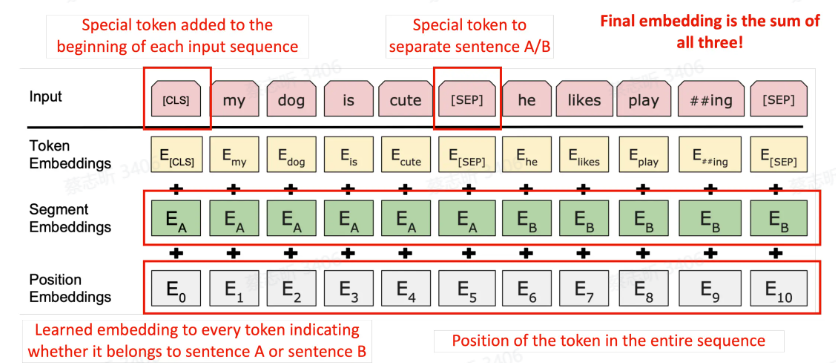
三种 embedding:词本身的,词属于哪一个句子,词的位置信息。Token 最终的 embedding:三者都考虑到。
Bert 效果很好,训练了两个模型,Bert base, Bert Large。对 NLP 领域最大的影响:预训练模型 规模越大,性能更好。
T5
把所有任务转换成 Text to Text 的模式。
用 Encoder 进行文本理解,再用 Decoder 生成。
把短语掩盖掉,Encoder 接收被掩盖掉的输入,Decoder 预测。
预训练范式
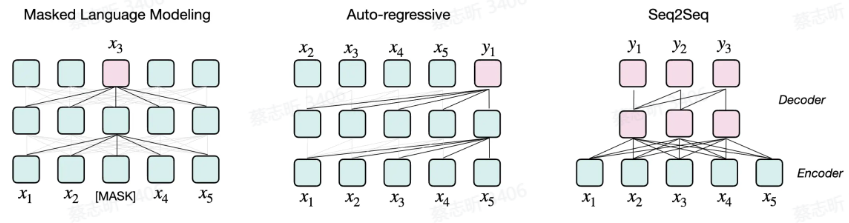
- Masked Language Modeling:像 Bert 那样,挖空,预测被挖空处的词。
- Auto-regressive:像 GPT 那样,仅根据前文内容来预测下一个词。现在的主流。
- Seq2Seq:像 T5 那样,Encoder 理解,Decoder 生成。
语言建模
用前面的 Token 预测下一个 Token。
语言建模是极致的多任务学习,在建模过程中会学习到各方面的知识能力。
只需要语料,无其他要求。但需要更丰富的数据,数据越多,越智能。
衡量语言建模:困惑度,预测下一个 token 的逆向过程。
困惑度通常定义为序列长度(即序列中词的个数)$N$ 和语言模型对词序列的对数概率的关系: $ PPL = e^{-\frac{1}{N} \sum_{i=1}^{N} \log P(w_i | w_{1}^{i-1})} $
| 其中,$P(w_i | w_{1}^{i-1}) $ 表示在前面词序列 $w_{1}^{i-1}$ 的条件下,预测词 $w_i$ 的概率。 |
计算整个文本的出现概率,把它取对数,除以 $N$,取相反数,为了防止他的数量不可读(确保精确度),添加一个指数。
困惑度(Perplexity, PPL)是常用于衡量语言模型好坏的重要指标之一。它描述了模型对于预测某一序列的下一词的可信度和不确定性。简单来说,困惑度越低,表示模型对预测下一词的准确性越高,模型对文本理解得更好。
GPT-1
1.17 亿参数,处理 7000 本书,先无监督预训练,然后在下游任务上进行监督式微调。
传统 NLP。
GPT-2
1.5B 参数,学习 40GB 文本,语言模型开始展示其可拓展性。
1
当在数百万网页的新数据集上训练时,语言模型开始在没有任何明确监督的情况下学习任务。GPT2在零样本设置中达到了最先进的性能,但仍未充分拟合训练语料库.
相关论文:Language Models are Unsupervised Multitask Learners
TODO:阅读该论文。

传统的 ML 范式导致了模型不能在多任务上进行泛化,通过扩大预训练的语料,参数,来解决这个问题。
GPT-3
现代大语言模型的转折点,泛化性。175B 参数,学习了 570G 文本。
1
对于所有任务,GPT3 都是在没有任何梯度更新或微调的情况下应用的,任务和少数示例仅通过与模型的文本交互来指定。GPT3 在许多自然语言处理数据集上都表现出色,包括翻译、问答和填空任务,以及一些需要即时推理或领域适应的任务。
拥有小样本学习能力与 情景学习能力(In Context-Learning),语言模型仅通过上下文演示就可以执行任务。
把 GPT-3 进行后训练:
- InstructGPT:更好的遵循指令
- ChatGPT:更好的对话
GPT-4
目前最好的模型,闭源。
传统 NLP:人构建一个任务,然后构建一个模型来完成这个任务。
GPT-4:任何可以转化成序列的任务,都可以处理。
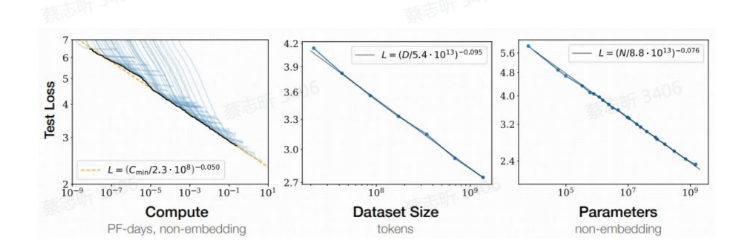
Scaling Law 扩增定律
扩增定律:随着模型大小、数据集大小和用于训练的计算量增加,语言模型的性能会平稳提升。
涌现能力:在模型的规模和复杂性增加到一定程度时,突然显现的、新的和往往是意想不到的能力。这些能力不是通过显式的编程或直接训练获得的,而是从大量数据和高度复杂的模型结构中自然涌现出来。
并行计算
ZeRO 框架:数据并行+模型并行
后训练
任何模型都需要做后训练(对齐 Aligned)。
- 场景适配:让模型在特定场景下完成特定任务
- 能力激发:激发模型在预训练过程中学到的知识
- 稳定和鲁棒:让模型输出稳健、安全的内容(幻觉问题)
- 价值对齐:让模型的表现和价值观与人类保持一致
对齐(Alignment):使 AI 输出人类期望的内容。(价值观,信息性,专业性)
对齐和微调的目标函数与预训练是没有区别的,都是语言建模的过程。
最初,对齐模型 = 在特定任务上对模型微调(预训练 + 微调),有监督训练。
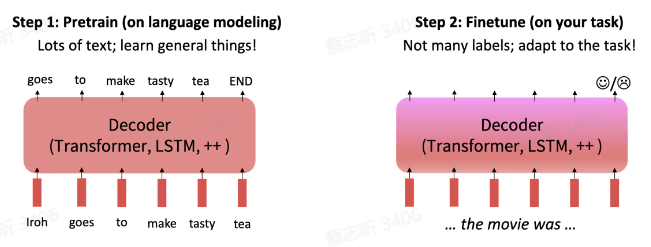
微调 GPT:对于每个分类任务,使用最后一个隐状态输入到线性层,线性层输出一个 softmax,这个 softmax 是一个类别的概率分布。
微调 T5:输入是 Token,输出也是 Token,所有的任务都变成序列到序列的方式,微调解码器来输出所需要的结果。
对齐方向:
泛化性:用更少的数据在更多的任务上达到更好的效果
效率:使用更少的参数、更少的计算资源,完成更多的任务
参数高效的微调:Delta Tuning
- 增量式方法:引入原始模型中不存在的额外可训练参数,只微调这些参数
- 指定式方法:指定原始模型或过程中的 某些参数变为可训练,其他参数保持不变
- 重参数的方法:把现有参数重新参数化,得到参数高效的形式
PEFT:huggingface 的库,可以尝试
OpenDelta:修改计算图,不修改代码库本身
适配器 Adapter
在每个 Transformer 层注入两个小神经网络单元 Adapter,Adapter 包含上映射(将高维度的输入特征映射到低维度的瓶颈空间)和下映射(将低维度的特征从瓶颈空间映射回到原始的高维空间)
只微调 Adapter 的参数,可调参数占整个模型的 0.5%~8%。
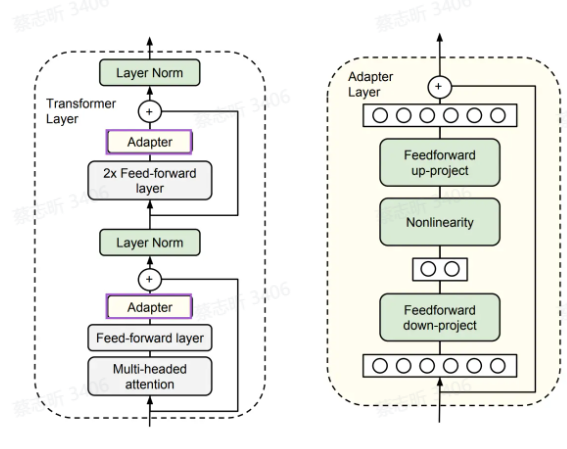
缺点:模型复杂度增加。
一个解决办法:梯子侧微调 Ladder Side Tuning
将 Adapter 移出主干模型,在主干模型外部搭建一个桥梯,从而节省反向传播的计算量。
将预训练模型视为一个“主干”网络,然后在每一层旁边插入一个较小的副网络。任务适配的过程中,这些副网络作为“适配器”,改变了特定任务的输入特征分布。
前缀微调 Prefix Tuning
在每个 Transformer 层的隐藏状态开头注入前缀(软提示),在 输入序列 的前面添加一组可训练的前缀向量来引导模型进行特定任务的学习,这些前缀向量在训练过程中被更新,而预训练模型的其他参数保持不变。
简化版本:提示微调 prompt tuning,在 输出 embedding 前面 加可微调矩阵。
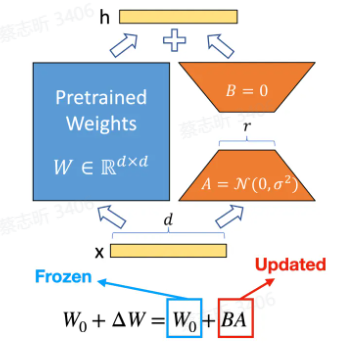
低秩适配 LoRA
LoRA: Low-Rank Adaptation of Large Language Models
在每个 Transformer 层中注入可训练的秩分解矩阵,分解神经网络矩阵参数的变化量,把它转化成低秩的形式,认为矩阵本质上是低秩的。
指令微调 Instruction Tuning
GPT-3:1750亿参数,无法微调,难以更新参数。
Prompt Learning:用提示词和示例(prompt)来统一不同的任务,把所有任务都用提示词描述。
指令微调 Instruction Tuning,通过不同的指令和答案来微调语言模型,本质上是从单任务的小样本学习,变成 跨任务的零样本泛化(模型在没有见过特定任务的数据的情况下,也能较好地完成该任务)。
InstructGPT:基于对话的指令微调。
大语言模型的核心是由指令微调带来的零样本生成能力。
数据:
- UltraChat:不针对性的构造任务,取消“任务”的概念,都是信息流,让模型自己在多样化数据中提取出能力
- Orca:把任务做到极致,把超大量的任务构造答案后形成数据
指令微调中,数据越少越好 or 数据越多越好?
基于人类反馈的强化学习 RLHF
准备一个语言模型,然后进行无监督训练,进行指令微调。
准备 偏序数据(给一个 prompt,和很多回答,基于一套标准(3H:有用性,无害性,诚实性)来评判和排序),训练一个 奖励模型(可以对输出进行打分),使用 Pair 对比的方式训练模型偏好,最大化好的 response 和坏的 response 的评分差值。
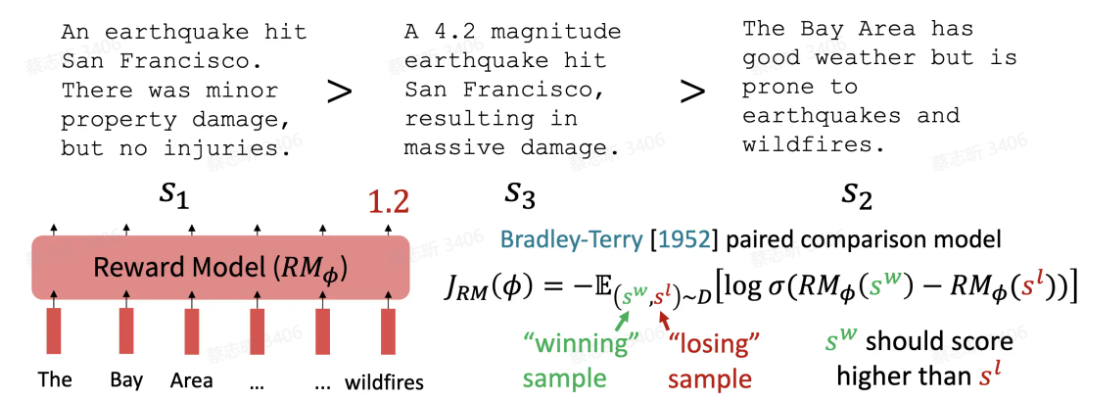
更新模型 :PPO 近端策略优化。让模型的输出得到的输出分数尽可能大,且让模型的参数变化不要过大。
DPO:省略奖励模型,直接从偏好中学习,而不是从强化学习中学习。
很少有开源模型使用 RLHF:数据稀缺(偏好数据),训练困难。
RLHF 的必要性:监督微调只有一个答案,与最终目标不一致。偏好很重要,可以进一步提升监督微调的大语言模型,偏好学习是构建更专业模型的必要步骤。
超级对齐
人工智能在许多方面已经超越了人类,我们如何 在难以评估的任务上对齐系统?
自主复制:具有高度自主性的高级AI模型,能够执行甚至优化其自身代码、架构或数据处理方式的能力。
如何确保大语言模型安全、友好、有用?