O1 Replication Journey Part 1
O1 Replication Journey A Strategic Progress Report – Part 1
[arXiv 2024] Yiwei Qin, Xuefeng Li, Haoyang Zou, Yixiu Liu, Shijie Xia, Zhen Huang, Yixin Ye, Weizhe Yuan, Hector Liu, Yuanzhi Li, Pengfei Liu
Abstract
和传统的研究报告不同,这篇主要是全面记录 o1 的复现工作,持续更新。
提出了“journey learning”,鼓励模型不止学习 shortcut,还要学习完整的探索过程:试错、反思、回溯。只用 327 个训练样本,在 MATH 数据集上的表现比传统监督学习高 8%。
Journey Learning: A New Paradigm Shift from “Shortcut Learning”
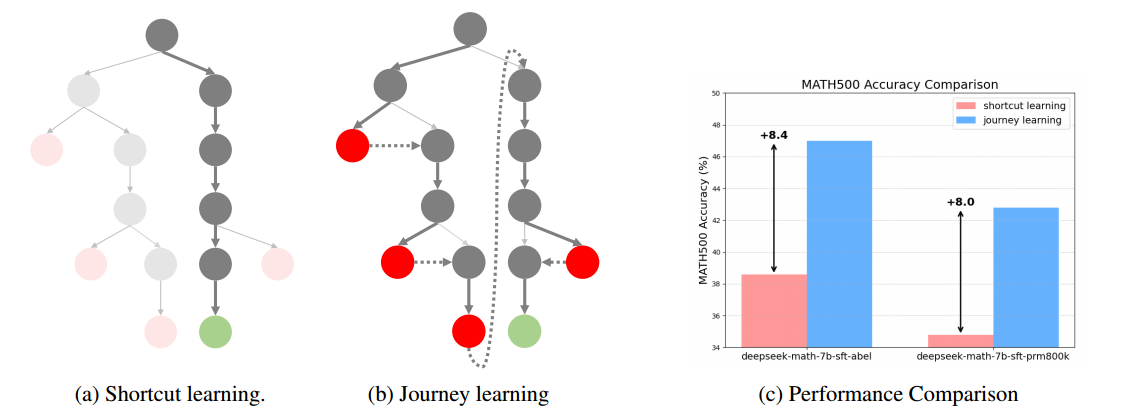
传统的 shortcut learning:从根节点(问题)到正解(绿点)的直接路径的监督训练
journey learning:在整个路径(包括试错和纠正过程)上的监督训练
基座模型:DeepSeekMath-7B-Base,在 Abel 数据集和 PRM800K 数据集上进行微调。
- Abel:由数学问题及其详细的解决步骤组成,旨在提高模型的数学推理能力。
- PRM800K:过程监督数据集,包含了 80 万个步骤级别的正确性标签,这些标签针对的是 MATH 数据集中问题的解决方案。
大部分现有的机器学习或大语言模型的训练方法(如监督微调)都可以被描述为“Shortcut Learning”,这种范式在复杂、动态和开放性问题上有局限性。Shortcut Learning 的特性:
- 结果导向:强调短时间内完成特定任务
- 数据依赖:性能改进往往依赖于增加训练数据数量,而不是提升学习算法
- 泛化能力有限:在训练数据以外的场景,性能可能急剧恶化
- 缺乏自我纠错能力:难以识别和纠正自身错误
| 特性 | Shortcut Learning | Journey Learning |
|---|---|---|
| 学习深度 | 表面特征和简单关联 | 深层因果关系和底层原理 |
| 推理能力 | 有限,难以处理复杂推理 | 强大,展现类人推理能力 |
| 自我提升 | 缺乏自我纠正机制 | 持续的自我评估和改进 |
| 泛化能力 | 有限,容易受数据分布变化影响 | 强大,能够应对新情况 |
| 创新能力 | 有限,难以解决新问题 | 高,能够生成创新解决方案 |
| 数据依赖 | 高度依赖大规模训练数据集 | 更注重质量和学习策略 |
| 可解释性 | 较差,通常被视为“黑箱” | 更好,能够追踪内部推理过程 |
| 道德考量 | 可能无意中放大数据偏见 | 更容易实现道德约束和调整 |
| 安全性 | 易受对抗性攻击的影响 | 更加稳健,能够识别潜在威胁 |
| 长期价值 | 在特定任务中快速出结果 | 为通用人工智能(AGI)发展铺平道路 |
| 人类类比 | 应试教育、速成课程 | 综合教育、终身学习 |
Background
过程奖励模型(Process Reward Model,PRM)
PRM 通过对推理过程中的每个中间步骤进行细粒度评估,提供比仅评估最终结果的结果奖励模型(Outcome Reward Model,ORM)更密集的反馈。评估中间步骤的正确性,提高后训练的质量。
实现:设计 prompt 并使用专有模型来评估;用对步骤进行标注的数据训练模型。
对步骤进行标注的高质量数据较难获得,于是可以将多步推理过程建模成马尔科夫决策过程,并使用蒙特卡洛树搜索来评估每一步的价值。
链式思维(Chain-of-Thought,CoT)
CoT 提示在模型生成答案前引导其生成一系列中间推理步骤,在处理复杂任务(如数学运算和常识推理)时表现出色。
内部思考(Internal Thought)
让模型在生成输出之前进行自我反思和推理,以提高其处理复杂任务的能力。
推理时间扩展(Inference Time Scaling)
在模型推理阶段增加计算资源以提升模型性能的策略。与传统的通过增加模型参数或训练数据量来提升性能的方法相比,推理时间扩展更注重在推理过程中充分利用现有模型的能力。
自我改进(Self-improvement)
- 监督微调:通过使用模型生成的高质量输出对模型进行进一步训练
- 偏好优化:模型通过学习其对某一查询生成的好坏响应对来优化自身表现
- 外部奖励系统:过程奖励模型/结果奖励模型
- 迭代自我改进
Exploration Journey
What does O1’s Thought Look Like?
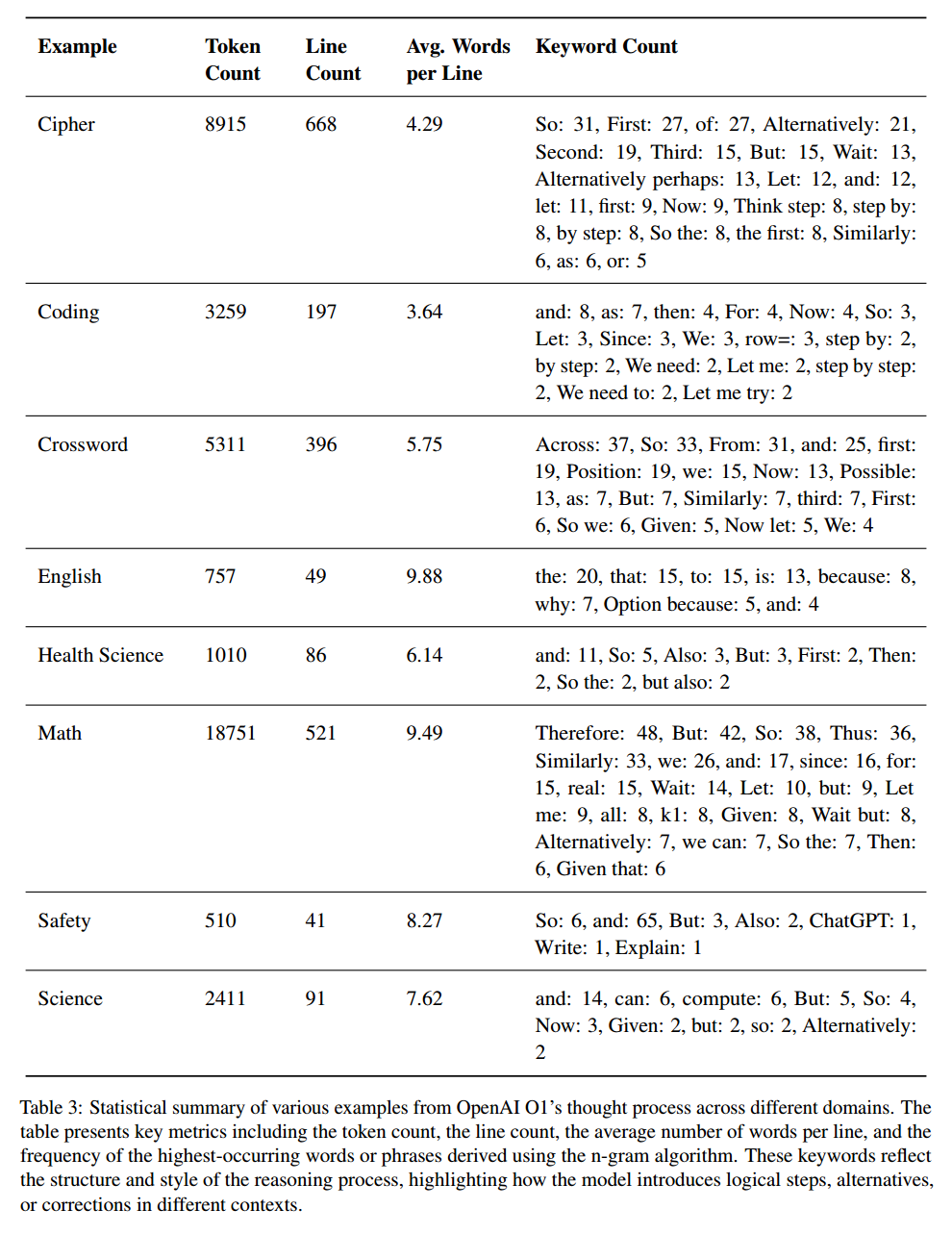
用 8 个示例分析,每种问题都有一个难度等级,分析输出的 Token 数量、行数、每行关键字数量,结果如下表,表明问题难度越高,推理步骤越长。
“关键字频率”这一个指标主要是识别表示推理过程的一些术语或连接词,如常见的 and,so,表示分支的 consider,if,possible,表示反思和自我纠错的 wait,alternatively。复杂度高的问题,这些关键字的频率高。
长思维数据的特征:
- 把复杂的问题分解成更简单的子问题,结构化的、有条不紊的问题处理的方法。
- 关键词,用 Therefore 表示结论,Alternatively 表示探索不同路径,Wait 表示反思,Let me compute 表示开始进行计算,这突出了模型的各个推理阶段。
- 经常重新评估和验证中间结果,递归回去验证。
- 进行假设,并在假设中不断调整方法。
- 求解结果前对结果进行验证。
How does Long Thought Work?
Journey Learning 使得模型可以模仿人类解决问题的过程,探索整个决策过程,考虑多种解决方案,从错误中学习,并获得强大的错误处理和自我纠错能力,促进了对问题的更深入理解。这还可以增强可解释性,因为模型可以提供详细的解决方案步骤,并解释他的推理过程,以及如何从错误中迷途知返。这不仅仅是延长计算时间。
How to Construct Long Thoughts?
在推理树上搜索
构建一个推理树,根节点是问题,其他节点代表一个推理步骤。回溯和反思需要基于错误的推理步骤,所以需要一个过程级的细粒度奖励模型,用这个模型来分析判断树上每个结点的正确性,然后在这个推理树上搜索,就可以把错误步骤整合到思维链上。
建议-批评循环
为模型预定义好一些动作(继续、回溯、反思、终止),让模型自己选择动作来构建推理树,如果树最终没有推出正确答案,向模型传递这个负面信号,引导他反思并纠正。
多智能体
多智能体辩论,一个智能体作为策略模型,持续推理,另一个模型进行批评,指示策略模型应当继续当前推理还是执行反思等操作。
人类思考过程标注
直接记录人类解决推理任务的过程。
How to Construct Reward Models?
首先要确定奖励模型的粒度。应当不止关注最终结果,还要关注 LLM 在反思、回溯等推理过程的能力,把粒度设定为 step level(步骤级别,对每个独立的操作或决策进行评估和反馈)。
用步骤级别的数据来微调开源奖励模型或专有模型,并在 PRM800K 和 MR-GSM8K 这两个数据集上进行评测。
PRM800K
PRM800K(Process Supervision Dataset)是一个过程监督数据集,包含了 80 万个人工标注的步骤级别正确性标签,主要用于评估模型在解决数学问题过程中的每一步推理的准确性。
每个问题的解决方案被分解为多个步骤,每个步骤都有对应的正确性标签,帮助模型在训练中更好地学习逐步推理的能力。
问题主要来自 MATH 数据集,涵盖了广泛的数学领域,确保模型在多样化的数学问题上得到训练。
MR-GSM8K
MR-GSM8K(Meta-Reasoning GSM8K)是一个用于评估大型语言模型元推理能力的基准数据集。
该数据集不仅关注模型最终答案的正确性,更注重评估模型在推理过程中的认知能力,如自我反思和过程优化。
How to Construct an On-policy Reasoning Tree?
用一个单步推理的策略模型,从初始问题(根节点)开始,向下生成 $w$ 个潜在的第一步推理步骤,然后递归下去,为 $w$ 个第一步推理步骤依次又生成一些潜在的后续推理步骤,直到达到最大深度,或推出最终答案。
用 Abel 数据集微调 DeepSeekMath-7B-Base 作为策略模型,用这个数据集进行微调可以控制模型进行单个1推理步骤的生成。
用奖励模型来剪枝,来控制生成树的成本。
- 用 math-shepherd 来对推理步骤进行打分,每次选得分最高的 $K$ 个保留。但是这个模型很难有效评估困难问题得推理步骤。
- 用 o1-mini 为每个步骤评估每一个步骤,并直接指出这个推理步骤是不是正确的,然后保留最多 $K$ 个正确的步骤
How to Derive a Long Thought from a Reasoning Tree?
得到推理树之后,需要导出长思考。推理树的每个节点都用奖励模型的打分标注,表明这个步骤的正确性,以及得出这个判断的原因。
- 构建 Shortcut,找到通往正确的叶子节点的路径。
- dfs 遍历树,把树上的节点按照是否在正确路径(Shortcut)上的标准分为两种,dfs 到在正确路径上的点,可以往子节点进行 $K$ 次探索,不在正确路径上的子节点也可以被探索。直到探索到错误的叶子节点,就回溯。如果 dfs 到不在正确路径上的点,就随机选一个子节点向下探索。未来考虑调整这些约束,来研究探索路径长度和最终模型性能的关系。
- 生成遍历路径后,可以把所有步骤连接,得到一个长思考,再把这个长思考用 GPT-4o 来修改润色,保留推理步骤,并增强思维过程的流畅性和连贯性。
How to Evaluate our Trials?
使用 benchmark 上的评估指标评估,并构建了一个可视化数据分析平台,可视化推理树及其对应的长思考,以及模型输出。支持对不同数据训出来的模型之间进行比较。
How to Train our Models?
在 deepseek-math-7b-base 上进行有监督微调(SFT)和直接偏好学习(DPO)。
有监督微调(SFT)
分为两个阶段:
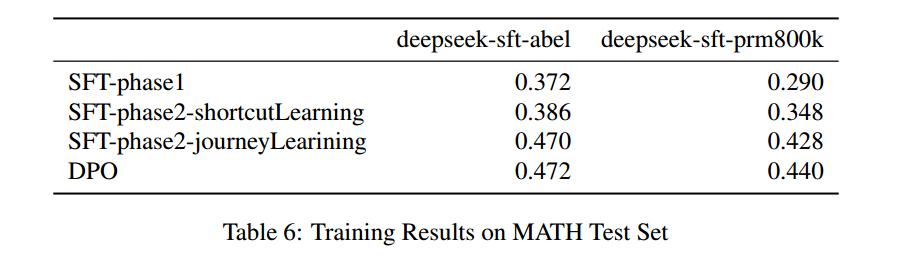
- ShortCut Learning:只用 ShortCut 来微调,在 Abel 和 PRM800K 数据集上微调,主要是让模型熟悉所需的 response 格式。
- Journey Learning:用构建的 long thought 来微调第一个阶段得到的模型,同时用 long thought 对应的 shortcut 也训一版来比较。训 3 个 epoch。
直接偏好学习
从 MATH 数据集里为每个问题生成 20 个答案,根据最终答案的正确性,把 20 个答案分为正面和负面,然后创建 5 个偏好对,来进行 DPO 训练。
结果:SFT 里,与 shortcut learning 相比,journey learning 提升明显。DPO 提升幅度较小,未来可以从结果级 DPO 过渡到过程级 DPO 方法。
What Would be an Effective Annotation Strategy for Human-AI Collaboration?
人类和 AI 协作流水线生成长思考推理数据,通过人类的少量标注,生成长的数据。标注者记录每次尝试、反思、联想、纠正,并且需要在数据中包含对常识知识的明确解释,以防止 LLM 的误解。
人工进行简洁精确的标注,AI 驱动生成最终的数据:
- prompt 让 LLM 把解决问题的过程细分成更精细的过程、更小的粒度。
- LLM 在生成时也应当进行反思,而不是被动地遵循指示。
- 鼓励 LLM 自行进行探索,让 LLM 不仅仅是接收信息,而是有自己的学习过程。