多模态agent文献略读(持续更新)
前期调研一些相关工作,粗浅看看introduction和方法,记录在这里,实验什么的就不细看了。
Large Multimodal Agents: A Survey
https://arxiv.org/abs/2402.15116
综述,介绍了 LMAs 的核心组成、分类、多智能体协作、评估、应用、总结与未来展望
感觉大部分讲的是视觉,以及模拟人类行为相关的,和生成式智能体比较相关的不多。
在应用部分,有一个小块提到了视觉内容生成和编辑。

Llava-interactive: An all-in-one demo for image chat, segmentation, generation and editing.
Chatvideo: A tracklet-centric multimodal and versatile video understanding system
Mm-react: Prompting chatgpt for multimodal reasoning and action.
看上去只有第一个是生成视频,后两个是视频内容理解,是视频生成文本,后续再看原文。
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
https://arxiv.org/abs/2303.11381
灵活的把视觉模型和语言模型结合起来,以解决复杂的视觉理解问题。
看起来是一个早期的工作,借助视觉模型把多模态信息转换成文本,让文本模型实现多模态理解。

每当 ChatGPT 需要图像或视频中的内容时,就寻求视觉模型的帮助。在 prompt 里添加每个模型的使用说明,并设置了口令,使得可以通过正则表达式来匹配并调用视觉模型。
ChatVideo: A Tracklet-centric Multimodal and Versatile Video Understanding System
https://arxiv.org/abs/2304.14407
先全面解析视频,在于用户交互时适当查询有用信息。把视频中对象的运动轨迹作为视频的基本单位,把对象的种类、外观、运动、轨迹存在数据库里,要用的时候就查出来给 LLM 参考做响应。
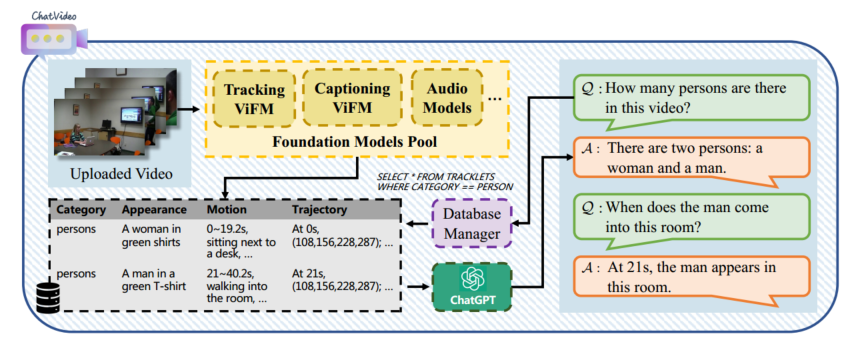
这项工作和上面的工作,还有一个叫 Visual CahtGPT 的工作,都是为了把 ChatGPT 和现有的视觉模型连接起来(而不是训练新模型),使他们交互,从而实现视觉聊天。
LLaVA-Interactive: An All-in-One Demo for Image Chat, Segmentation, Generation and Editing
https://arxiv.org/abs/2311.00571
这好像就是实现了个应用。
拼接了三种模型的功能:LLaVA 的 visual chat,SEEM 的图像分割,GLIGEN 的图像生成与编辑。
Related Works 里介绍了当前 LMM 的多模态理解或交互的方法:
训模型让模型具有多模态输出能力
GILL [8], CM3leon [29], Emu [20], DreamLLM [3], Kosmos-G [19] and MGIE [4].
在模型推理时调用其他视觉模型
Visual ChatGPT [25], X-GPT [30], MM-REACT [28], VisProg [7], and ViperGPT [21]

实现了:编辑图像,生成新图像,进行与图像内容相关的对话。可以根据用户画的轨迹执行相关操作。

VideoAgent: Long-form Video Understanding with Large Language Model as Agent
https://arxiv.org/abs/2403.10517
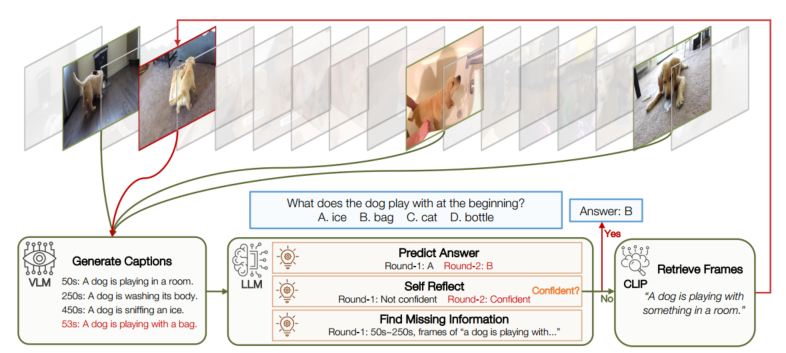
长视频理解。
像人一样理解视频,人是先浏览几帧了解上下文,然后迭代搜索其它帧来收集足够信息回答问题,最后汇总所有信息,做推测。
流程如下:
- 均匀采样 N 帧,VLM(vision-language model)用文本描述图像,提供给 LLM。
- 决定下一步是退出搜索回答问题,还是确定还需要哪些信息,继续搜索。根据当前的信息回答问题,然后自我反思评估置信度。
- 找新帧:LLM 先挑一些视频片段,然后用 CLIP 去匹配与查询文本相似度高的帧。
- 为新的帧生成描述,然后和之前的描述排序和拼接起来。
GenArtist: Multimodal LLM as an Agent for Unified Image Generation and Editing
https://arxiv.org/abs/2407.05600
第一个图像生成和编辑合一的系统。
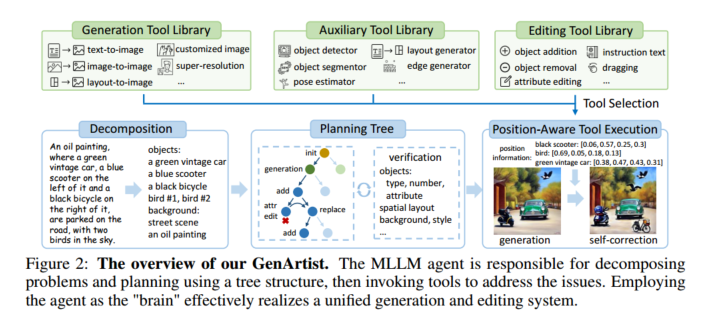
MLLM 来统筹规划管理整个系统。先分解对象和背景信息,或者把编辑操作分解为多个具体的操作;建立一颗树,节点由初始节点、生成节点、编辑节点组成,自修正机制,每个生成节点都有一个由编辑节点构成的子树;然后遍历树,调用工具来进行操作;最后验证。
在调用工具之前,执行一个 Position-Aware Tool,主要是解决输入中提供的位置信息不足的问题。位置信息补充(调用其他工具补充位置信息)、位置信息介绍(对输入图像进行检测分析生成边界框,为 MLLM 提供空间参考)
GENMAC: Compositional Text-to-Video Generation with Multi-Agent Collaboration
https://arxiv.org/abs/2412.04440
重点是关注 Compositional,组合式文本。
“第一个用多智能体协同解决组合文本生成视频的范式”。
组合式文本到视频生成(Compositional Text-to-Video Generation)是一种技术,旨在根据复杂的文本描述生成包含多个对象、属性、动作和运动的高质量视频。与传统的文本到视频生成(Text-to-Video Generation)相比,组合式方法更注重将不同的元素组合在一起,以准确反映复杂的场景和动态。
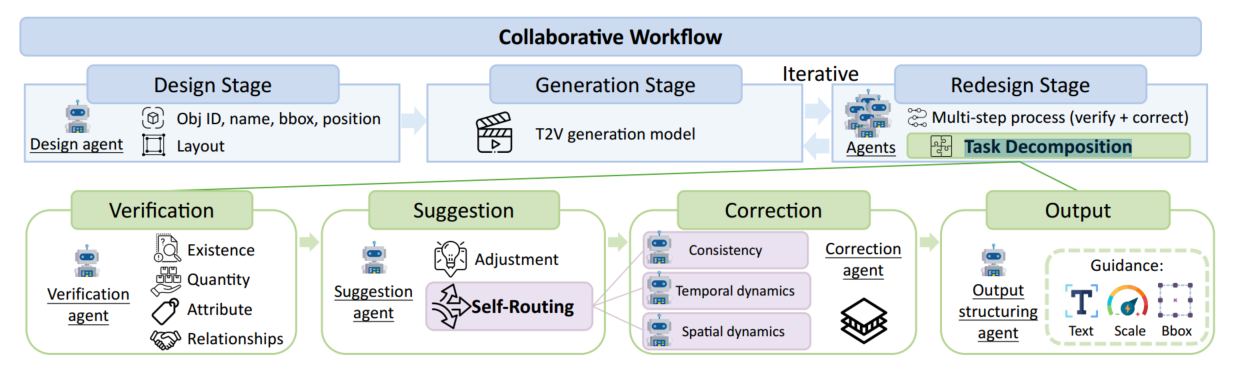
三个步骤,design, generation, redesign.
design:把文本转换为结构化的布局,让 LLM 为每个帧和每个实例生成边界框,包括其对象id、名称、大小、位置。
generation:用 text-to-video 模型把结构化布局转化成视频,引入 LVD 方法(Llm-grounded video diffusion models)
redesign:核心,检测生成的视频和提示词之间的差别,调整 design,采用多个 MLLM 协同的方法
任务分解,每个子任务用一个专门的智能体来解决
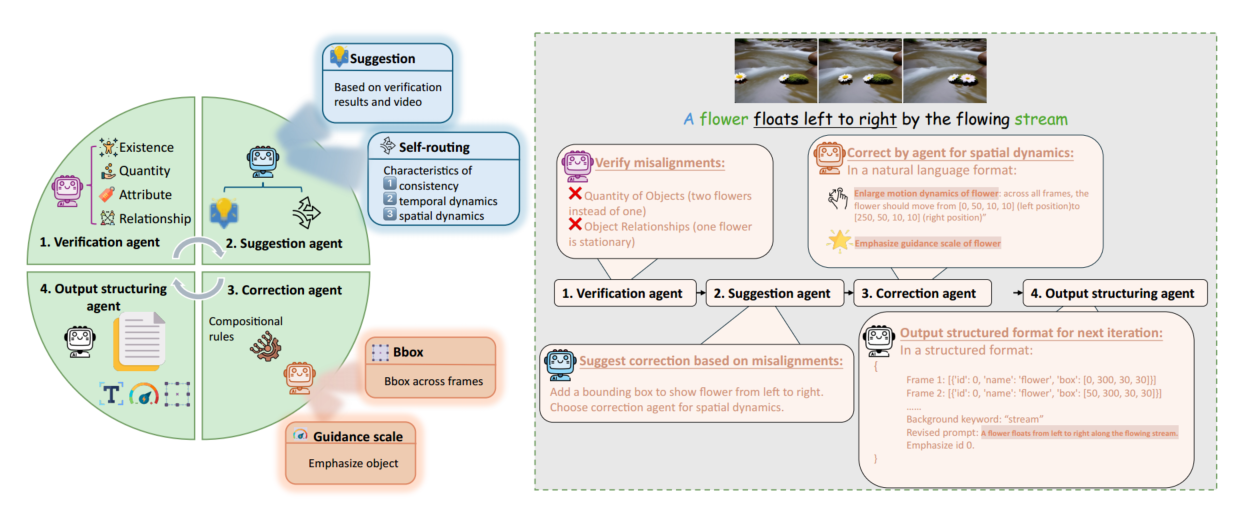
- 验证:存在性、数量、属性、关系
- 建议:改进设计,选择合适的修正智能体
- 修正:更改边界框设计和,输出修正方案(三个智能体,时间一致性、动态变化(对象属性更改、动态操作)、运动(对象位置变化),由建议智能体选择)
- 输出结构化:输出格式化后的 design
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs
https://arxiv.org/abs/2401.11708
Kubrick: Multimodal Agent Collaborations for Synthetic Video Generation
https://arxiv.org/abs/2408.10453
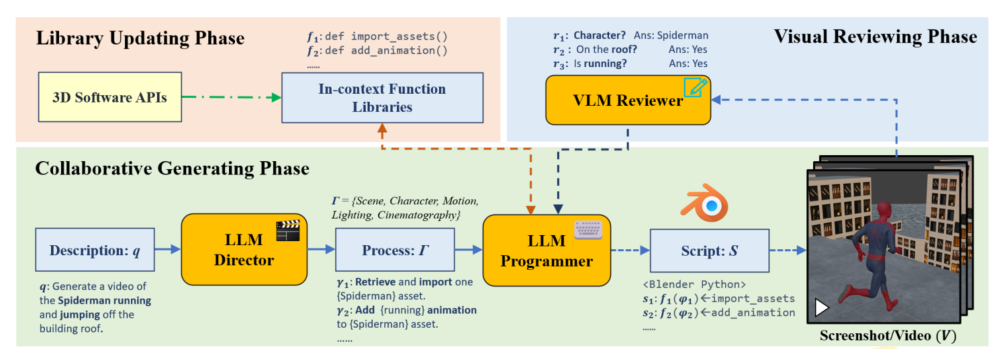
协作生成,先用类似 CoT 的方法拆分子过程:场景、人物、运动、光照、运镜,让 LLM Director 去分别生成描述,生成完了让 LLM Programmer 去对每一部分生成代码,用 Blender 渲染。
反馈,用 VLM Reviewer 为每个子过程打分,并提出改进建议让 Programmer 修改代码。
评估,评估人物运动和运镜,并把反馈返回给 LLM programmer 进一步改进脚本。
更新函数库,有的时候改进脚本需要增加或者删除函数库。
RAG,放了 Blender 的文档和 Blender 生成视频的教程,每个 agent 使用都加 RAG。
Anim-director: A large multimodal model powered agent for controllable animation video generation
https://arxiv.org/pdf/2408.09787
多模态大模型驱动的 agent,动画视频生成。
LMM 作为导演来编排动画。
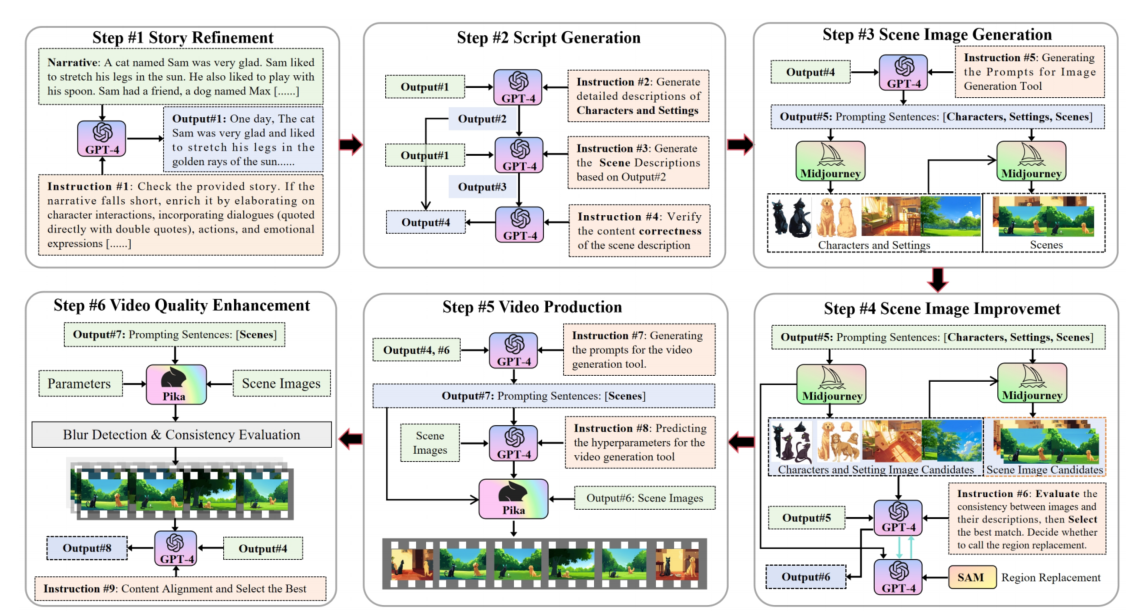
流程:故事扩写与优化,剧本生成(人物和背景,场景,校验),场景生成(先文生图,生成人物图像和背景图像,然后文+图生图,),场景优化(关注一致性,场景一致性、任务一致性),视频生成,视频质量优化(生成十个选最优)
DreamFactory: Pioneering Multi-Scene Long Video Generation with a Multi-Agent Framework
https://arxiv.org/abs/2408.11788
清华&卢森堡大学
关注点:Multi-Scene Long Video Generation
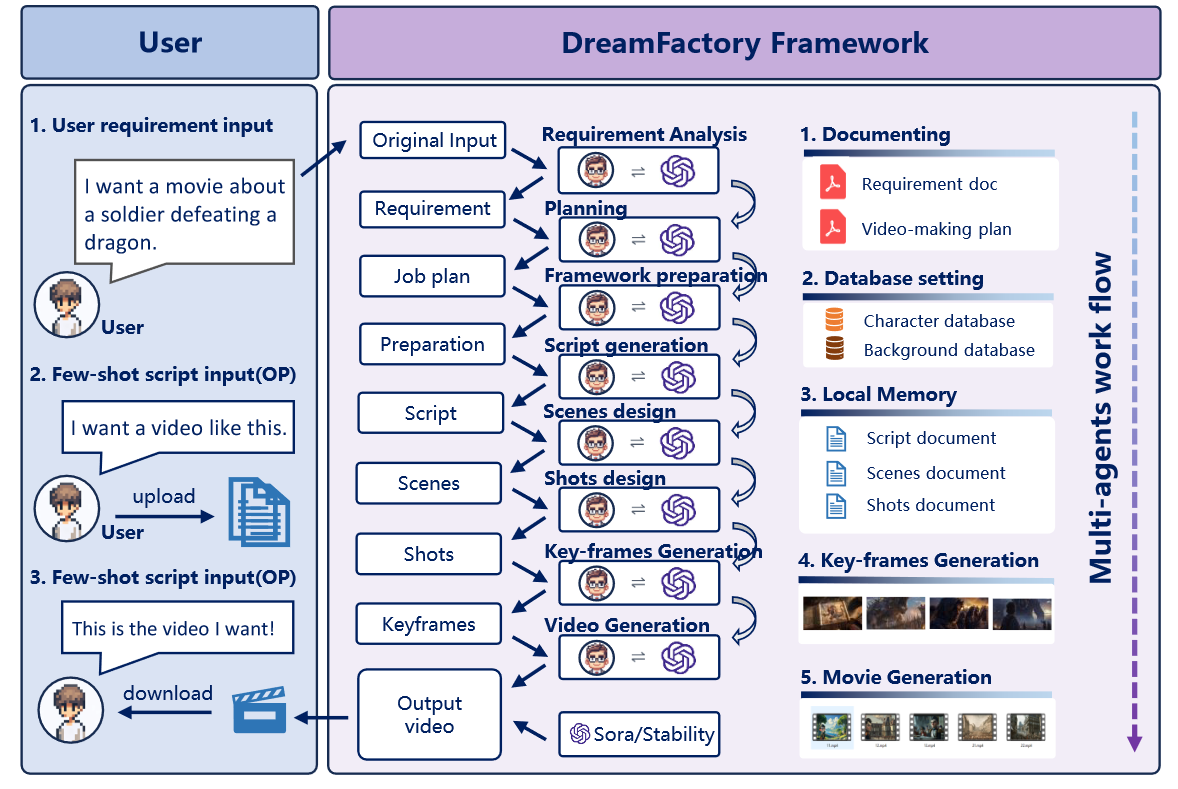
制定了自己的工作流。
如何保证关键帧的一致性?
short-term memory
模型本身有短期记忆能力;加入一个监视器,每帧生成后进行检查。
long-term memory system
提取初始帧的关键信息,每次生成的时候都把这个加进去;前一帧的信息也会在生成时考虑到。
实验:
评估关键帧生成人物(T2I)
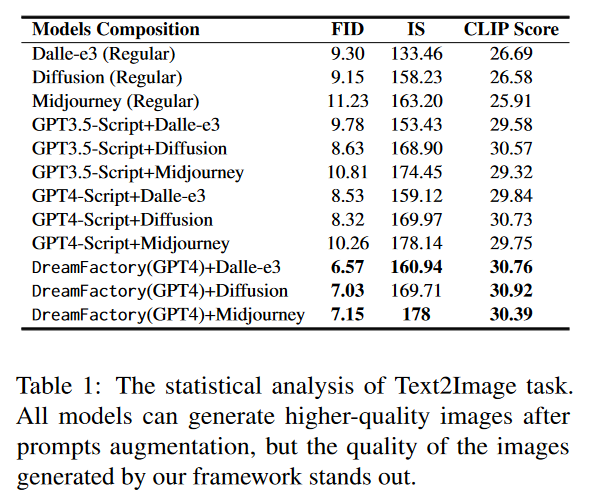
评估I2V

人物一致性
对于每帧中的人,和后续所有帧的人物计算面部相似度,取平均
场景一致性
用GPT-4V对每个关键帧分类,看最多类别占总关键帧数的多少
StoryAgent: Customized Storytelling Video Generation via Multi-Agent Collaboration
https://arxiv.org/abs/2411.04925
ICLR2025 在投。
指出了 Mora 和 AesopAgent 的不足:人物一致性,定制故事视频生成( Customized Storytelling Video Generation (CSVG))。针对这两个不足做的新范式。
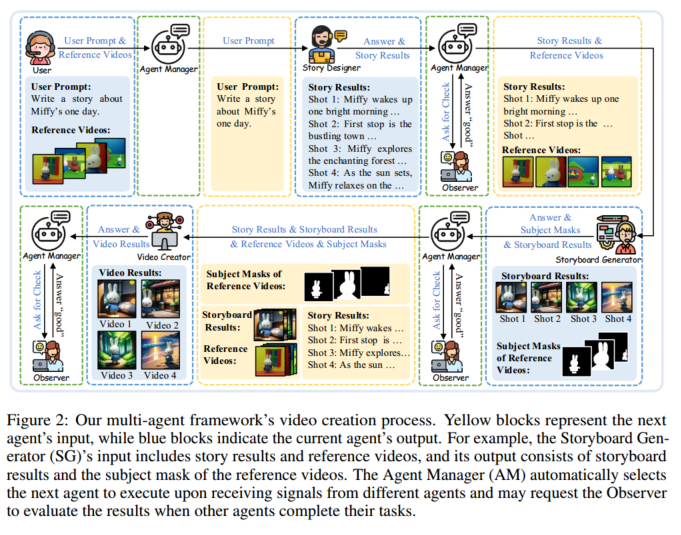
把 CSVG 分解成几个子任务,每个智能体负责一个:
故事设计,为每个场景写详细的情节
生成 storyboard
保证多个图片间人物一致性:先生成一组,然后用 LangSAM 把主要人物 mask 出来,用微调的 AnyDoor 生成定制的人物填充 mask
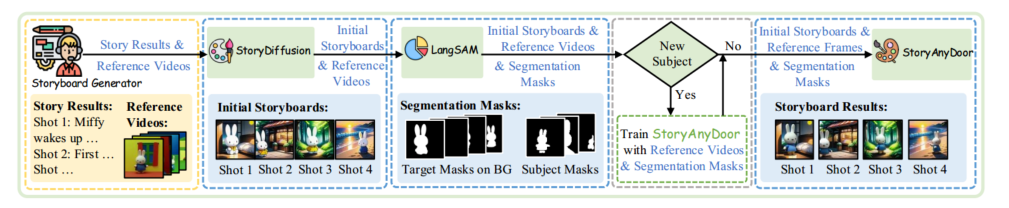
生成视频(I2V)
视频内部角色保真度:LoRA-BE
引入了角色词向量 Block-wise embedding,训练阶段更新 LoRA 参数和这个 embedding,让模型可以辨认并复原这个角色,推理阶段 3D U-Net 去噪时用到新注意力层和 embedding。
agents manager
审查,反馈
From Sora What We Can See: A Survey of Text-to-Video Generation
https://arxiv.org/abs/2405.10674
DriveDreamer-2: LLM-Enhanced World Models for Diverse Driving Video Generation
https://arxiv.org/abs/2403.06845
MultiMedia-Agent: A Multimodal Agent for Multimedia Content Generation
https://openreview.net/forum?id=2JN73Z8f9Q
VideoAgent: Self-Improving Video Generation
https://arxiv.org/abs/2410.10076
ChatCam: Empowering Camera Control through Conversational AI
https://arxiv.org/abs/2409.17331
港科,NeurIPS 2024
开源,仓库地址 https://github.com/DarlingHang/ChatCam
Motion-Agent: A Conversational Framework for Human Motion Generation with LLMs
https://arxiv.org/abs/2405.17013
MotionAgent: Fine-grained Controllable Video Generation via Motion Field Agent
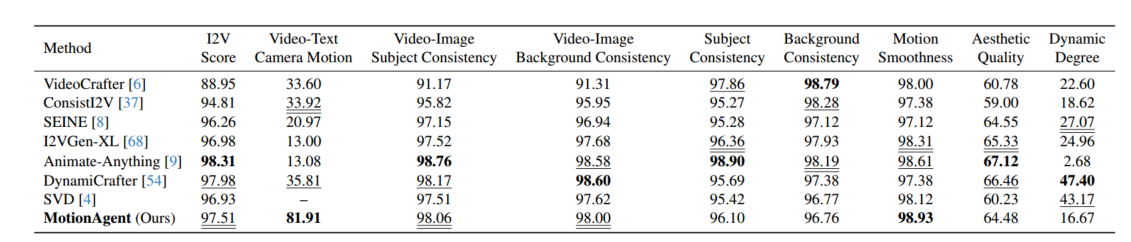
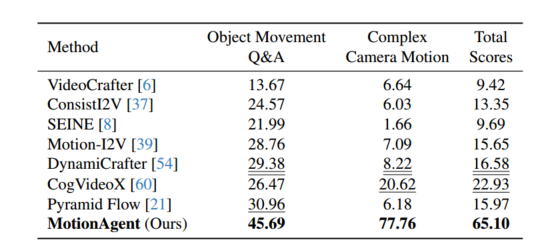
https://arxiv.org/abs/2502.03207
南洋理工&阶跃星辰
关注的是用文本引导动作控制。
先用一个 motion field agent 生成对象轨迹和相机轨迹,然后用一个 analytical optical flow composition module 把这两个轨迹转化成 optical flow maps,最后用 Stable Video Diffusion 作为 base model,用 optical flow adapter 作为 motion control module,生成最终视频。
流程:
Motion Field Agent
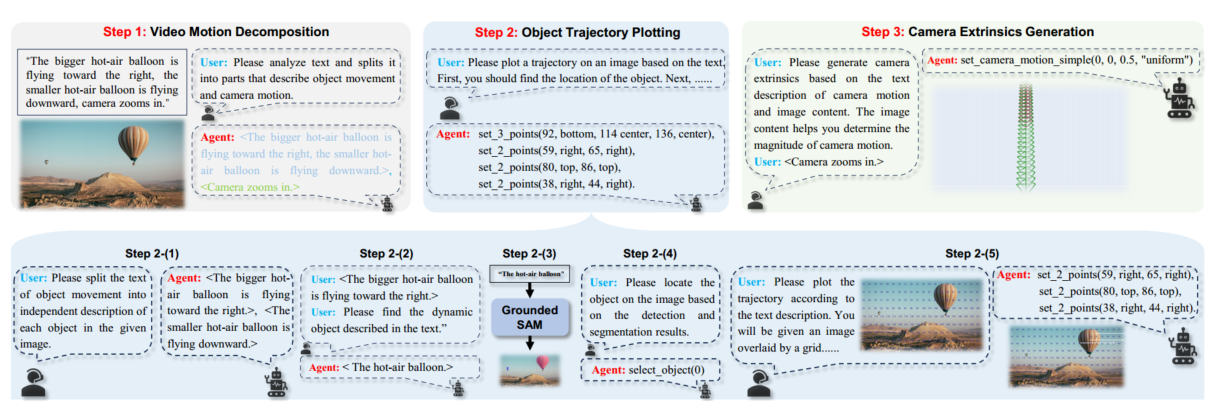
分解:对象移动、相机移动
绘制对象移动轨迹:对象识别(把文本中每个对象的运动分割出来,然后到图像里找到对应的对象,并mask上),轨迹绘制(定位对象确定起点,网格选择方法绘制轨迹,把图像划分成 N*M,选格子作为轨迹点)
相机外部参数(Camera Extrinsics)生成:综合文本(明确指示相机的运动)和图片(帮助确定相机运动幅度)生成相机外参
Controllable I2V Generation
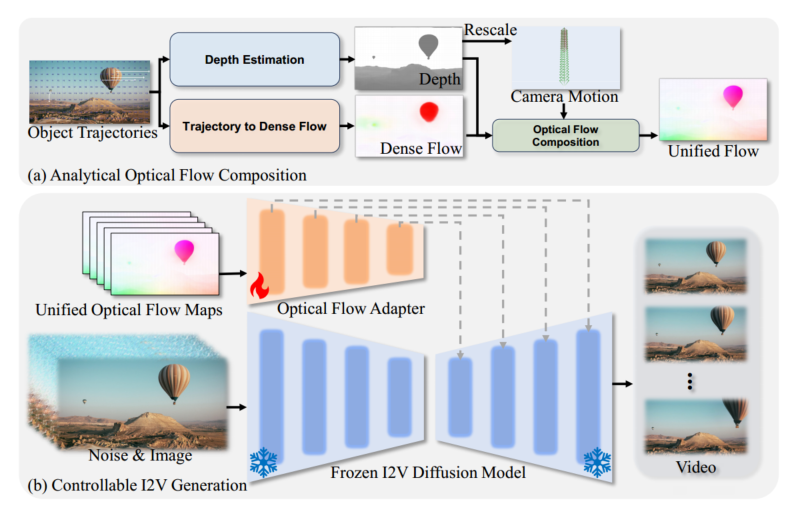
生成光流图
用 Metric3D 估计图像的 depth,然后用 CMP 估计物体运动的光流,结合相机外参计算得到最终的光流,生成视频。
Optical Flow Adapter 微调
近似计算得到的光流会有误差,可能导致运动不合理。微调:监督学习,Unimatch 计算真实视频的光流,让 Analytical Optical Flow Composition 生成的光流尽可能接近真实视频的光流。
评估:general & controllable(为VBench里的图像设置新的 prompt,使对象运动描述更详细,相机运动提示更复杂)